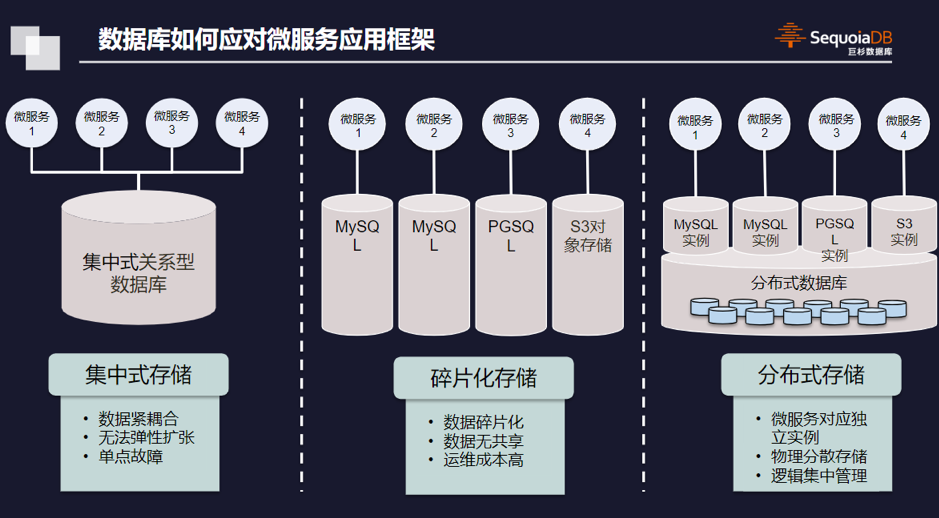
存储在线
存储在线虚拟化是云计算的重要基础,虚拟化在带来资源灵活性和利用效率极大提升的同时,在性能方面打了折扣,为了提升云端服务的性能,市场上开始出现了Bare metal(以下统一称作:裸机服务器)这样的裸机服务器,这是另一种优化方案。在更多极致优化性能的场景中,一个重要的思路是做offload,把原本许多需要系统调用、内核操作的工作交给别的物理设备来做,绕开系统,绕开CPU,简化流程,简化操作,把一些与业务无关的任务用别的设备来做,换句话说,就是计算机系统的各部件分工更明细了,让效率提升。
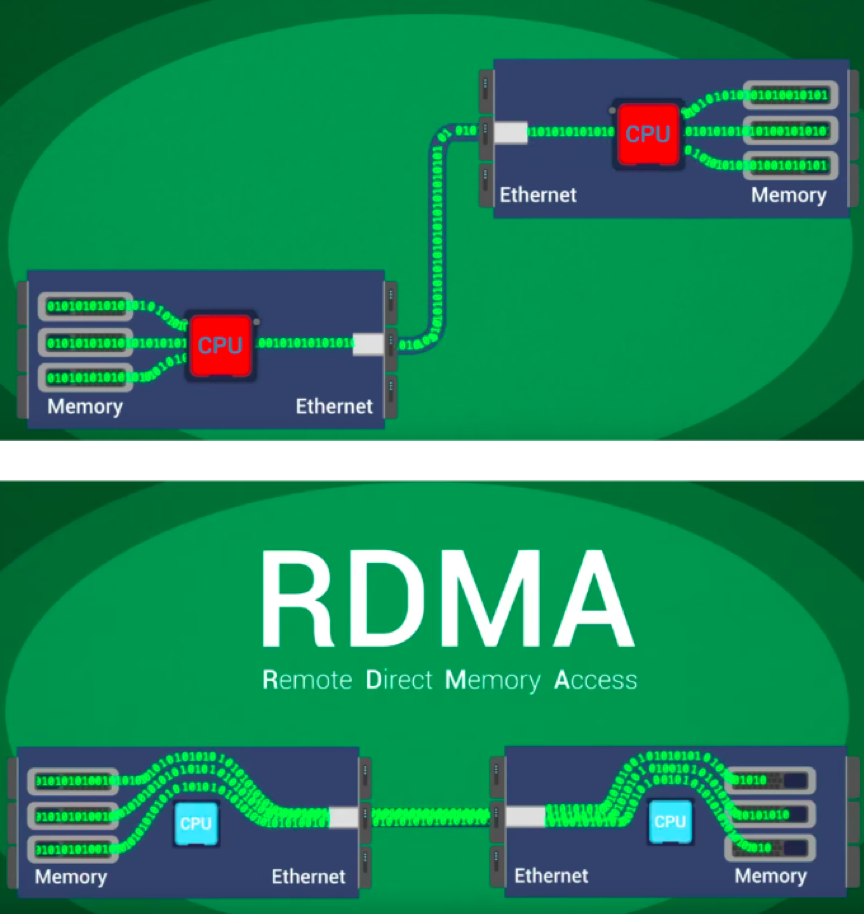
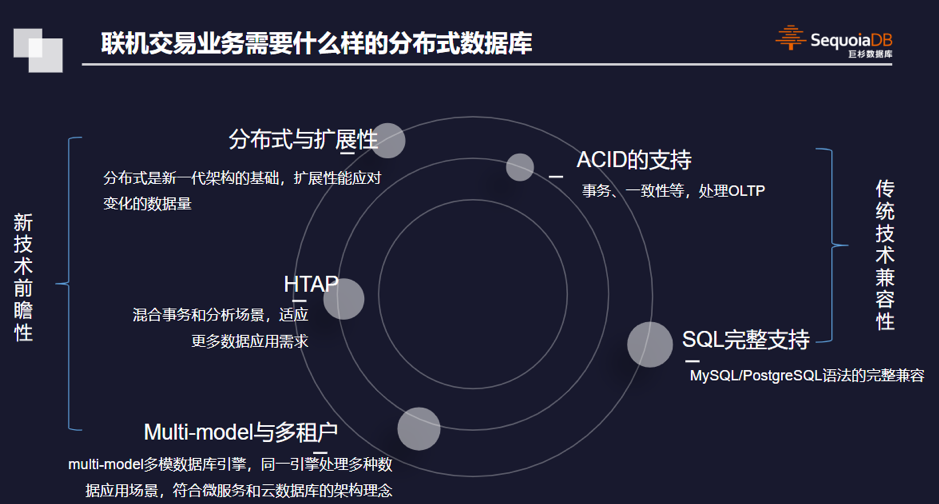
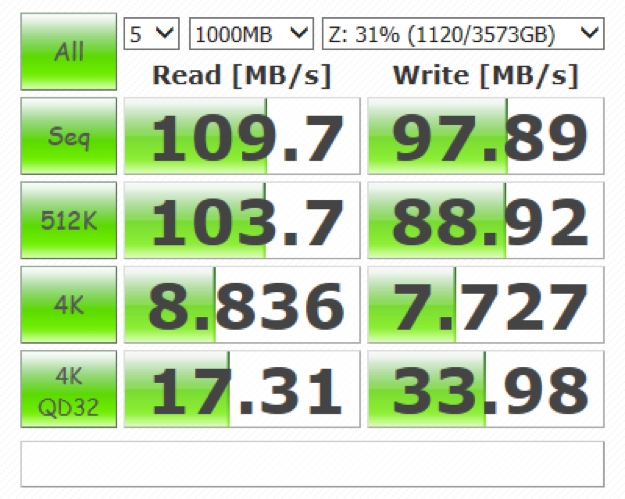
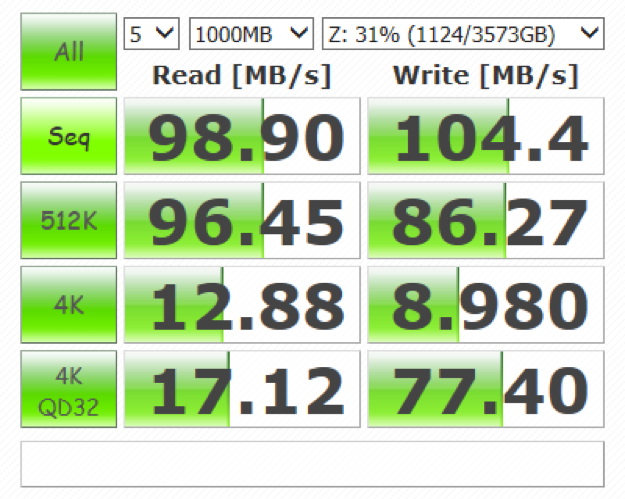
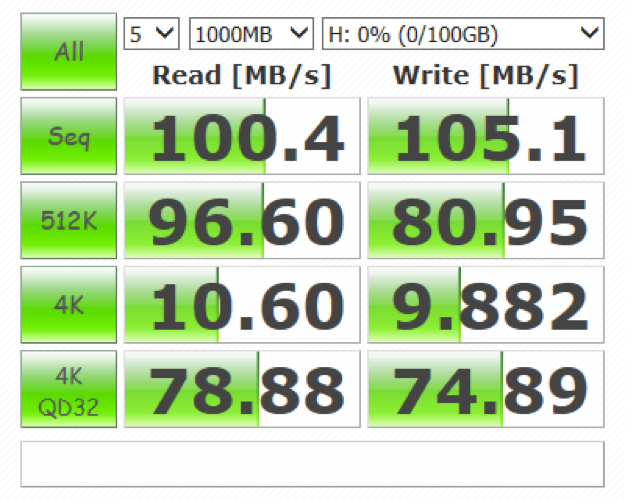
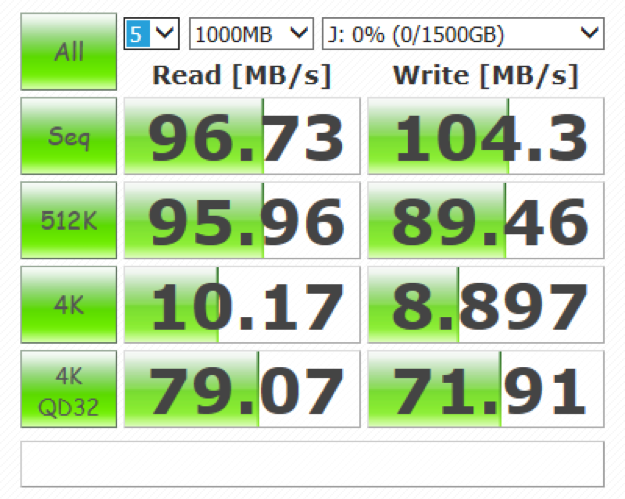
有无RDMA前后
典型如RDMA,就是绕过了CPU操作的流程,把原本CPU要做的事儿交给了别人。类似的offlload创新有很多,在超大规模云计算中心这种效率至上的地方,AWS的Nitro也在做同样的事儿。
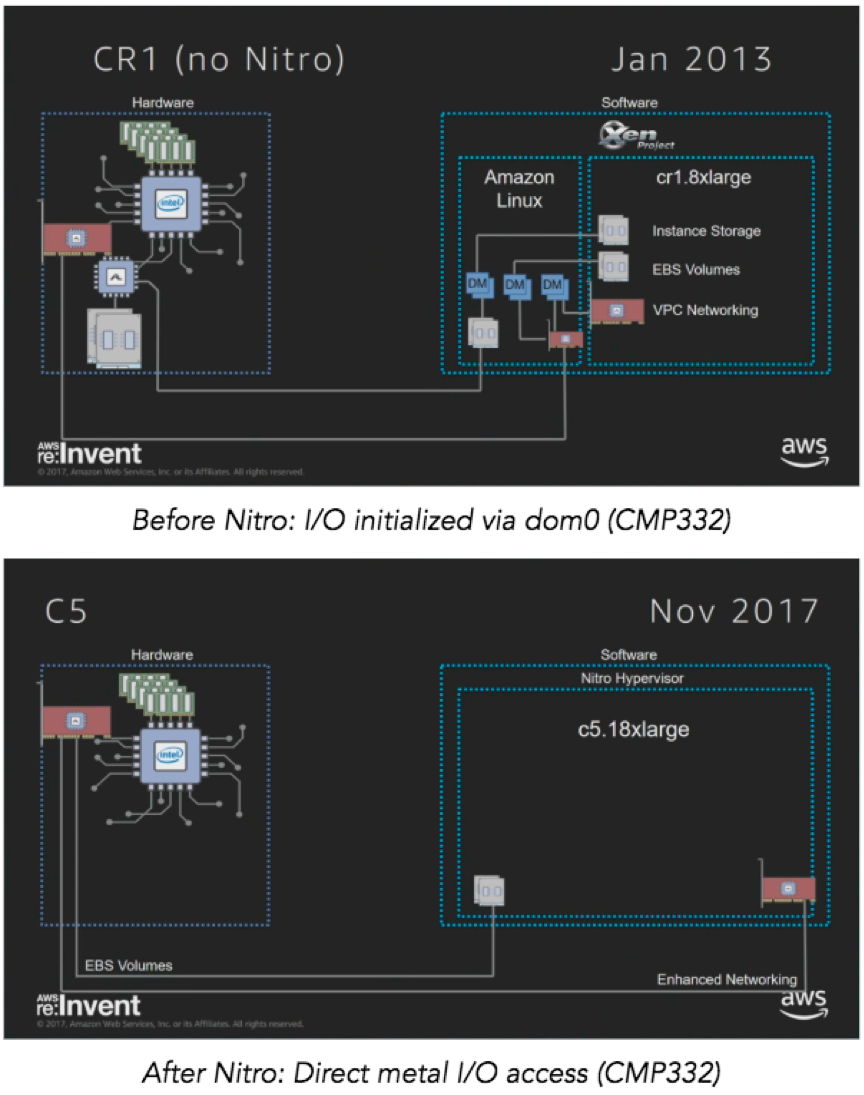
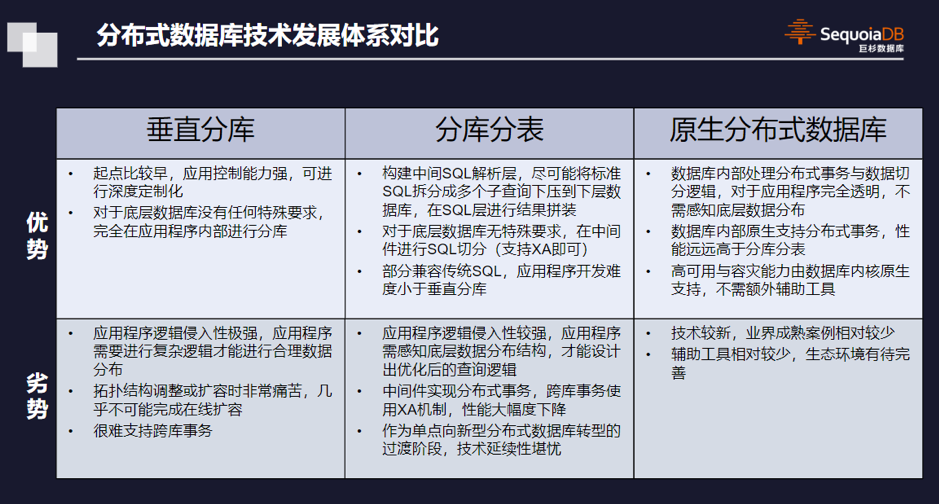
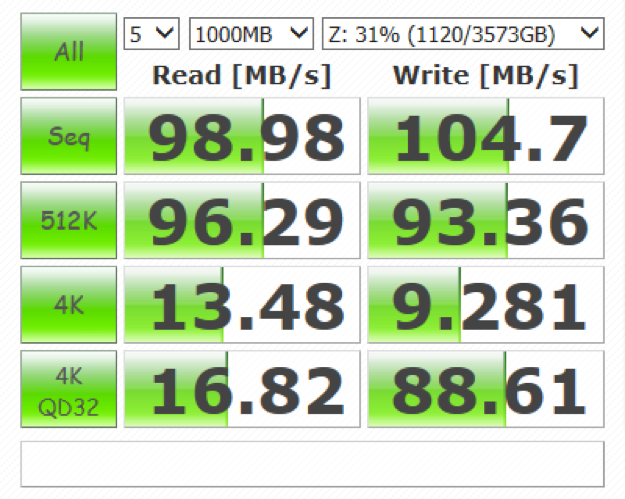
有无Nitro架构上发生的变化
从上图可以直观的感受到,有了Nitro系统之后,系统构建的复杂度明显降低。在实际实现当中,Nitro分为三大方向,且三大方向相互独立。

这三大方向分别是:
NitroHypervisior:专有硬件上承载hypervisior,实现近似裸机服务器的性能表现;
NitroCards:专有硬件承载存储、网络功能,以及控制EC2实例的业务逻辑;
Nitro安全芯片:硬件层的安全验证能力;
NitroHypervisior
Nitro首先是一块ASIC芯片做成的系统,插在云数据中心的物理服务器上,把原本需要运行在CPU上的软件hypervisior要做的事儿自己做了。
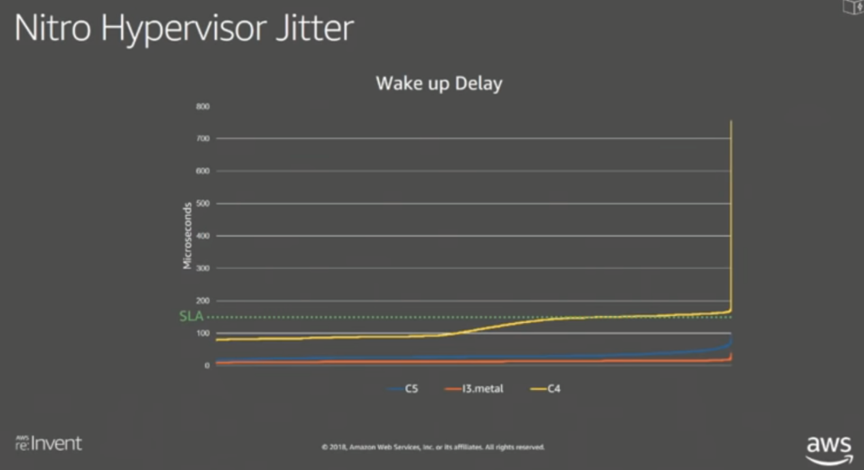
图自AWS re:Invent 2018
把原来虚拟机软件要做的事儿交给专有硬件来做之后发生了很多变化,最最最主要的就是性能上的变化。AWS首席技术布道师Jeff Bar在一篇博客里写道:有了NitroHypervisior的实例跟裸机服务器主机相比,性能只差了大约1%,这一微小差别很难察觉出来。上图是一张在2018年AWS re:Invent大会keynote上公布出来的图,它展示了采用Nitro hypervisior的C5实例与没用Nitro的C4,以及裸机服务器主机的唤醒时延对比,C5主机表现与裸机服务器主机差别非常小。
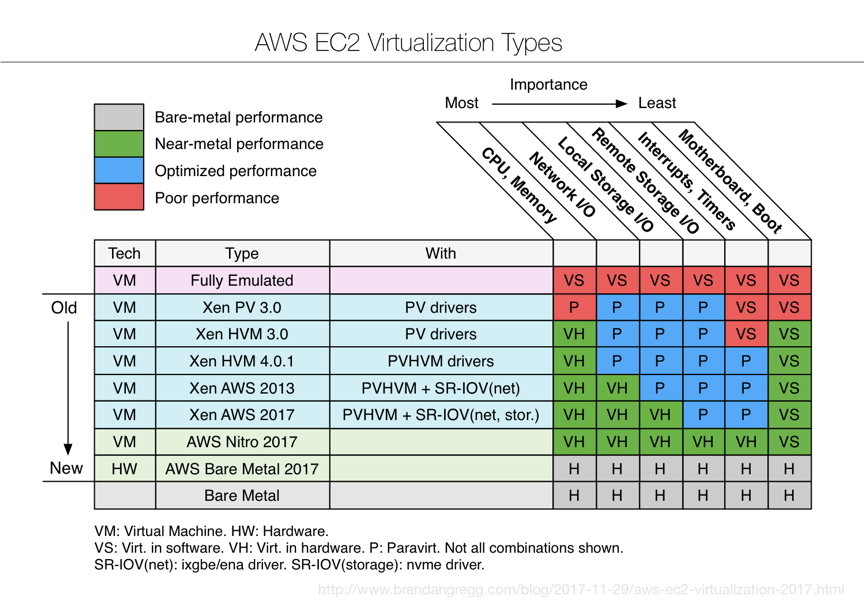
Nitro的引入是AWS EC2的极具突破性的创新,上图回顾总结了EC2多年来使用的虚拟化技术的变迁史,从上到下的历代更新中,用硬件直接干的事儿越多,从纯软的虚拟化到半虚拟化,性能越来越好,最开始连CPU和内存都是虚拟的,后来,Nitro用ASIC硬件运行的基于KVM的Hypervisior取代了原来的Xen虚拟化方案,CPU、内存、网络、存储都成了硬件来支撑的了,现在可以说是真正的硬件虚拟化了,性能嗖嗖的上来了。
在性价比方面,Nitro将原本在通用CPU里运行的Hypervisior抽离到了专有硬件上,offload掉了原本需要服务器自己做的事儿,所以,用户买到的资源就不再打折扣了,比如CPU和内存资源就更足量了,如果说腾出来的CPU计算资源量不好描述的话,那么内存容量的足额交付就非常直观了。
那么,性价比能差多少呢?
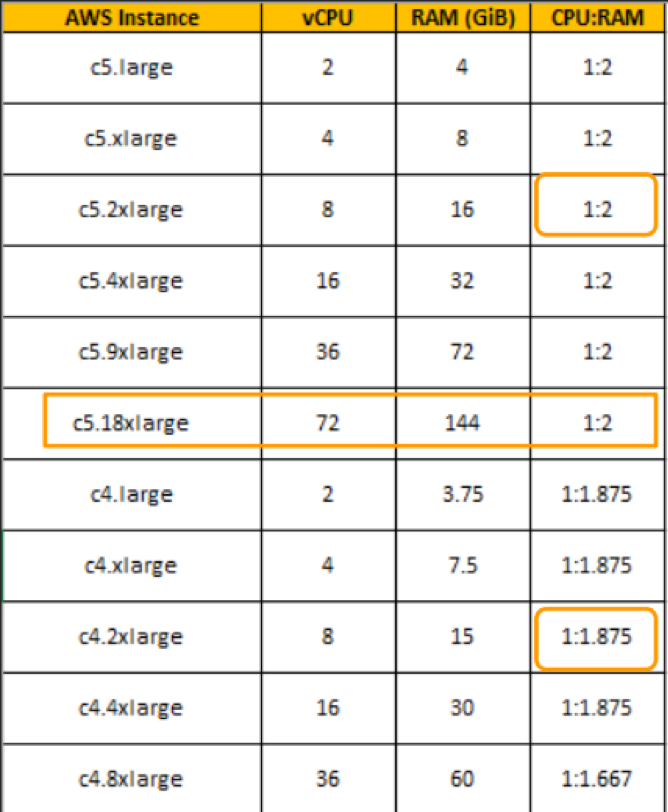
以C5实例为例,从新一代的C5实例开始,AWS未来几乎所有的新型主机会用Nitro。对比一下,原来C4系列主机CPU:RAM的配比是1:1.875,现在变成真正的1:2了,当然计算资源也有类似的提升,用户能买到能足额交付的资源,或者说买到的资源都能用于业务上了,对于用户来说意味着性价比的提升。
今年2月份的一则消息显示,AWS中国的用户已经能使用包括计算优化(Compute-optimized)的C5和C5d实例,内存优化(Memoryoptimized)的实例R5和R5d实例,说起性价比提升,AWS给出的数据显示,从C4升级到C5的话,中国用户能享受到的性价比提升高达49%。另外,R5相对R4实例,每个vCPU能提供额外5%的内存空间,而且,R5相对于R4价格降幅也高达49%。
可以说,C5最大的特点就是性价比提升,这一做法比打价格战高级多了。对于云主机这种需求和要求都非常明确的商品来说,性价比对用户还是非常有吸引力的,AWS表示有数千客户都开始用上了C5的实例,包括大名鼎鼎的Netflix也对C5相对于C4的性价比赞赏有加,在实际使用中,Netflix发现C5实例比C4实例的性价比提升了40%。
当然,以上性价比数值都是AWS或者Netflix根据精确的计算算出来的,普通用户想直观感受下性价比差异的话,可以参考这一网址(https://aws.amazon.com/ec2/pricing/on-demand/),中国用户可查看(https://www.amazonaws.cn/en/ec2/pricing/ec2-linux-pricing/)。
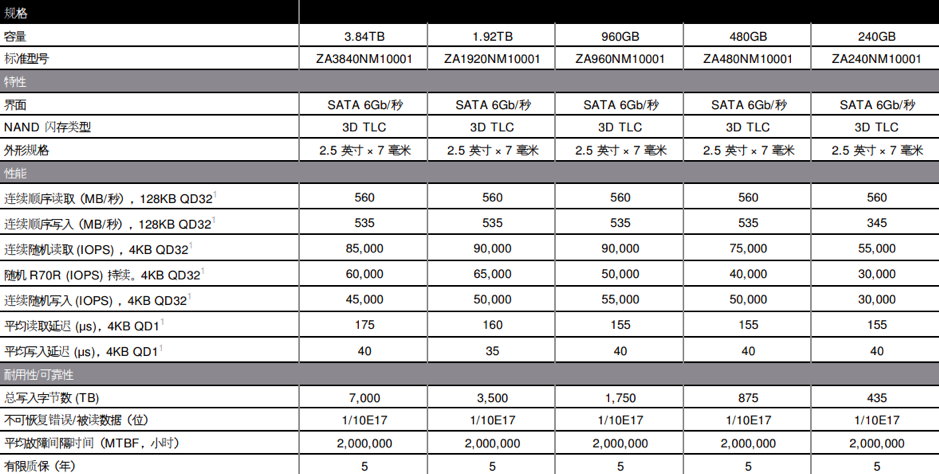
笔者我也简单感受下吧,简单查看如下价格表会发现,同样是36核的实例,C5内存比C4的内存生生多出来12GB,价格却降低了大约20%,C5果真是加量还降价了,有兴趣的朋友也可以自己看看。
![]()
![]()
截图自AWS中国官网
当然,如果能在整体能力上有所提升就再好不过了,从实际数据可见,C5实例的各方面配置相比C4也有明显提升。
在计算能力提升方面,一方面要靠NitroHypervisior做offload节省出来的计算资源。另一方面,当然要靠新一代的CPU了,AWS的C5实例采用的是英特尔定制的第一代至强可扩展处理器,支持最高72vCPU和144GB内存(保持计算优化型主机1:2的配比),支持AVX 512指令集强化的向量和浮点计算能力,而C4最高只有36vCPU和60GB内存配置。
Nitro Cards

存储方面,在C4时代,Nitro card就用在了EC2的实例存储当中了,而C5d系列实例在存储方面进行了强化,支持本地的NVMe SSD。本地的NVMe的性能优势毋庸赘言,在IOPS和延迟方面都有显著提升。目前,除了C5d以外,M5d还有裸机服务器的EC2实例也都支持本地的NVMe存储了,凡是实例命名里有字母d的都是支持本地NVMe SSD。另外,在支持远程EBS块存储的时候,还采用了非常先进的NVMe over fabric技术。
总之,NitroCard充当NVMe控制器的角色,也从hypervisior做offload,充分利用硬件的能力。不仅如此,Nitro Card还在硬件层实现了EC2实例与存储之间的隔离,隔绝了用户间的一些性能干扰。
VPC网络方面,Nitrocard充当网卡,充当ENA控制器的角色,充当SDN功能的专有硬件,从hypervisior做offload,让服务器的CPU不用预留资源去处理网络事务。此外,除了类似Nitro Card充当NVMe控制器时候的隔离性能干扰的特性外,AWS的这块特殊的网卡还支持许多高级的网络加速特性。
Nitro的功能相对独立,可以根据需求灵活搭配来组建,Nitro Card 控制器是一个大管家,可以管理Nitro的Hypervisior、存储、网络以及安全功能。AWS通过它来在后台进行系统管理。
Nitro 安全芯片
在安全方面其实就没什么offload了。我们知道,各种设备的firmware对系统的安全有序运行都非常关键,为了正确管理这些firmware,Nitro 安全芯片一方面追踪服务器上各种控制器的firmware的IO操作,一方面还能升级管理这些firmware,这是原来的服务器做不到的。在启动服务器的时候,Nitro芯片会做各种底层的安全验证,以此来保证系统安全。
结语
以上就是Nitro系统的主要职责,它将存储、网络、管理以及安全的能力都offload到专有的硬件上了,省去了与通用计算设备抢占资源的麻烦,节省资源,提升效率,作为AWS平台的一部分,用户对于Nitro是不可见的,而且,用户不需要知道有Nitro这个东西,各种使用体验与原来没有Nitro的实例几乎一样,然而,用户拿到的资源更多了。
看来用专有硬件做专业的事儿,比通用硬件带来的效率要高的多,不然怎么会提升性价比呢。云巨头在信息产业有举足轻重的作用,除了在业务上对传统IT带来冲击以外,在IT架构本身也带来了许多新变化,云巨头需要定制适用于超大规模数据中心的服务器、网络和存储等基础硬件,当考虑到规模效应时,将一些领域做得深入细致也是必然趋势,AWS的Nitro在EC2的offload上开了个头,从不跟友商比较的AWS,这次又以一种新的方式,恐怕要逼得纯粹的云主机价格战无路可走。
2019年全球闪存峰会将于2019年8月22-23日在中国杭州国际博览中心召开,大会由中国存储器产业联盟,中国计算机学会信息存储专委会,武汉光电国家研究中心,百易传媒(DOIT)共同举办,将有中国计算机学会存储专委会、武汉国家光电研究中心、SNIA等多家业内顶尖机构的重量级嘉宾参与其中,有众多业内知名大咖,意见领袖共襄盛举。