
2019年5月上旬,巨杉数据库在DTCC(2019中国数据库技术大会)上隆重发布了旗下核心分布式数据库产品SequliaDB 3.2版本,并就当前业内需求趋势,数据库的创新理念和创新之处进行了一番介绍。
作为一款金融级分布式关系型数据库,巨杉数据库连续两年入选 Gartner 数据库报告,在超过50家大型商业银行的核心生产系统规模使用,其中单集群最大物理节点数达到135个,单集群最大存储容量达2.1 PB,集群管理最大记录数1318 亿条,在容灾安全性方面能做到RPO = 0 , RTO小于15秒。
分布式数据库是数据库领域的一大创新,与传统集中式数据库有很大差别。分布式数据库相对于集中式数据库有多重优势,在成本,可管理性以及对新型业务的支撑方面都有体现,比如在微服务架构方面就有很大优势。
分布式数据库能更好地支持微服务架构

容器技术,以及与容器技术紧密相关的DevOps、微服务等技术非常流行,被许多人认为是继虚拟化技术之后,IT基础设施领域的又一大创新,对于企业敏态业务发展至关重要,围绕容器技术需要企业IT架构作出调整,对于数据库的需求也有很大改变。
王涛提到,很多企业都在从基于传统数据库的烟囱式开发向微服务架构转型,微服务体系架构中,每个微服务都需要提供数据持久化能力,用户希望每个微服务所应对的数据量能够无限弹性扩张。
支撑微服务的话,是用集中式数据库还是分布式数据库呢?
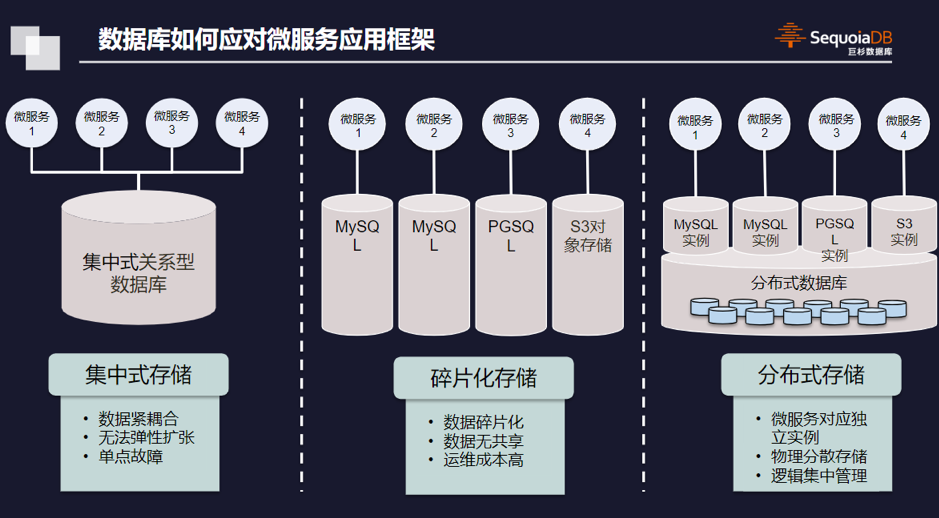
王涛介绍说,如果使用传统集中式数据库,那么对于应用程序的改造相对比较小,对DBA运维人员的成本比较低,但由于数据紧耦合,既无法弹性扩张,又可能存在的单点故障的隐患。
另一种做法是每个微服务对应一个独立的小数据库,比如使用MySQL或PostgreSQL,这样能够解决集中式存储的问题,但因为每个微服务都使用独立的数据库,会使原本集中的数据分散到很多不同的设备中,会造成数据极度碎片化,数据在微服务之间无法共享,而且运维成本极其高昂。
碎片化带来什么难题呢?
王涛介绍说,一些互联网公司生产系统中维护着两三万套MySQL数据库,这样的架构下想要进行企业内部的数据整合视图是极为困难的事儿。数字化转型时代,数据是企业的核心资产,在大数据以及基于数据的人工智能技术在企业逐步落地和发展的过程中,这样的数据架构显然是有很大问题的。
巨杉数据库的分布式数据库能很好地解决这一问题。一方面,分布式数据库解决数据的弹性扩张的问题,使每个微服务可以不受底层数据存储限制进行扩容。另一方面,可以解决微服务应用架构中数据严重碎片化的问题。
巨杉分布式数据库如何解决这一问题的呢?
巨杉分布式数据库的做法是用统一的分布式数据库做底座,上层可以创建成百上千个数据库实例,同时,应用无需感知每个数据库实例底下对应的资源。
对单个应用来说,这样的数据库与传统标准数据库完全一致,但是又能做到弹性伸缩。管理方面,所有的物理设备从逻辑上进行统一管理,降低管理成本。数据共享方面,不同实例里的数据可以进行共享。
这样的分布式数据库既兼容了传统数据库技术,同时又是面向未来的。
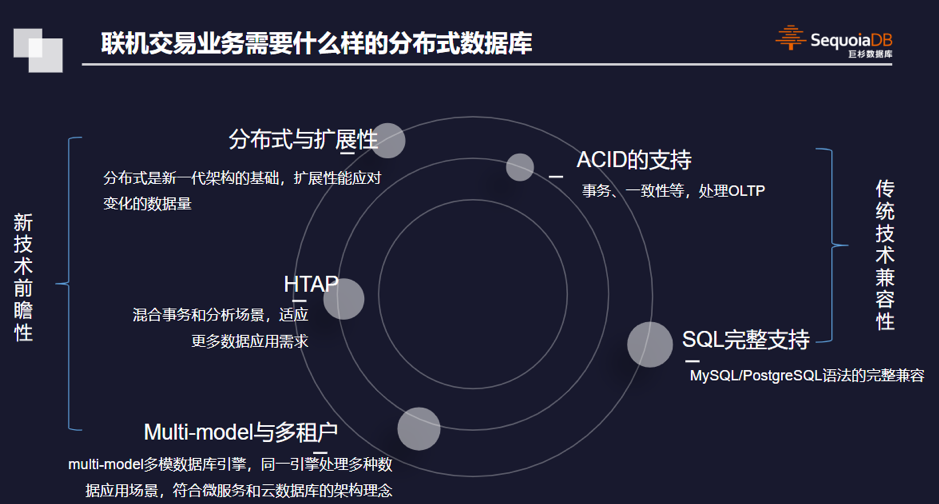
在兼容传统数据库方面,作为金融级数据库,巨杉数据库有完整的ACID支持,事务和一致性保证,而且,巨杉数据库完整支持SQL语句,与传统数据库如MySQL/PostgreSQL的语法完全兼容,用户和管理员可以像以往一样用数据库,应用程序也无需做什么改动。
完整的ACID支持意味着能同时支持一致性和安全性,王涛强调“绝对不能为了上分布式牺牲数据的一致性和安全性”,他认为,新型面向联机交易的分布式数据库必须对传统ACID有完美的支持,与传统Oracle DB2的数据安全性一致性保持兼容。
在面向未来的新特性方面,巨杉数据库有三点创新:
第一个是分布式与扩展性,这其实是分布式数据库的核心价值,它可以根据数据量的变化,实现存储层和计算层的弹性扩展,能在数据库的层面以服务资源池的形式提供数据库访问能力。
第二个在于多模式访问接口,其实主要就是因为如今的服务类型、应用需求等多样化,对数据库接口类型的要求也日益多样化,所以,分布式数据库要支持多类型数据管理和多种模式的访问接口。这点与分布式存储也非常类似,面对多样化的应用,存储也需要多元化的接口类型。
第三个方面其实考量共享架构的资源隔离问题,当一个数据库同时处理HTAP交易和分析混合处理业务时候,如何不影响联机交易业务的性能表现?巨杉分布式数据库的资源池内可对交易与分析业务进行物理资源隔离实现数据的物理隔离,性能方面互不干扰。
作为一款金融级的关系型数据库,巨杉数据库在数据安全和容灾方面也颇有造诣。巨杉数据库原生支持数据库内核级别的高可用以及跨数据中心灾备能力,目前已经实现异地容灾备份,可满足“三地五中心”的容灾支持。同时,巨杉数据库在异地容灾基础上,实现了数据异地多活,目前已经实现双中心同时读写,中心切换RPO为0和RTO达到秒级,提供了“超金融级”的数据安全保障。
分布式数据库的演进
分布式的概念已有很多年,分布式存储,分布式数据库都是如此,分布式数据库在历经多年的发展当中不断迭代,分布式数据库技术发展体系可分为三类:垂直分库、分库分表和原生分布式数据库。
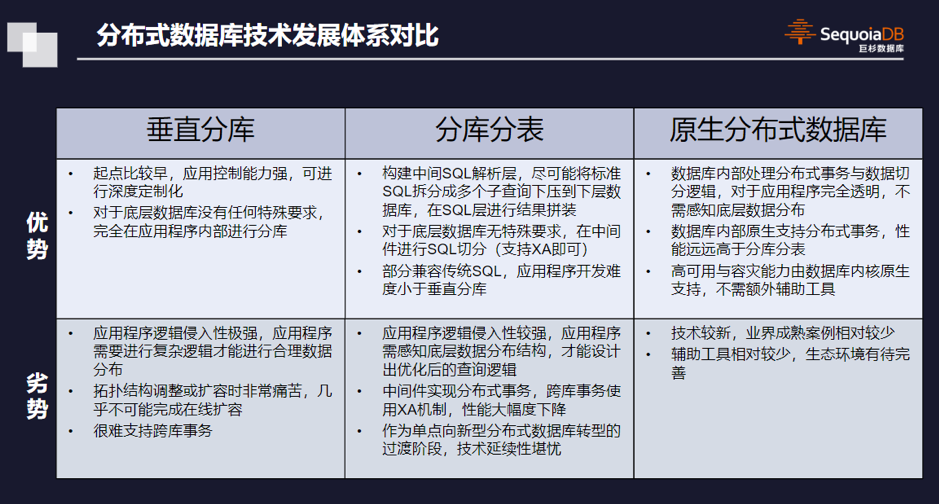
王涛介绍说,最传统的是垂直分库,通过定义好的应用规则,按照规则找到数据库实例,然后再直接获取连接进行查询。这种方式的缺点在于,跨数据库的事务难以实现,需要非常多的定制化开发。
还有一种方式是分库分表。做法是在应用程序和数据库之间构建一个SQL解析服务,将SQL翻译成底层每个数据库所看得懂的子查询,把查询下发给底层的传统数据库。这种机制是从集中式架构到分布式架构的过渡状态,同时,由于对于应用无法做到完全透明,一般来说需要在应用拼装SQL的时候指定很多参数或比较独特的语法。
最后一种则是通常所说的原生分布式数据库,常见的有巨杉和蚂蚁金服的OceanBase分布式数据库。原生分布式数据库是底层完全从零开始研发,完全抛弃小型机体系,基于PC服务器硬件架构设计的分布式数据库,将高可用、容灾、分布式等机制天然融入到数据存储体系的方方面面。
以巨杉数据库为例,能够保证在与MySQL 100%兼容的前提下实现对应用完全透明的分布式能力。开发者不需要关注一个表存了几亿还是十几亿记录,只要在建表的时候配置好容量和横跨多少台物理设备,数据即可自动在库内进行均衡,从应用来看就像访问标准的表一样直接进行读写请求。

SequoiaDB v3.2版本在分布式存储层和数据库实例层均增加了许多新特性。底层的分布式存储层作为资源池,负责数据存储、分布式事务控制等,数据库实例层则提供对上层应用程序的SQL服务,用户可创建结构化实例,也可以创建非结构化实例,可应用在包括联机交易、数据中台以及内容管理三大场景下。
作为一款开源分布式数据库,在巨杉数据库的官网上已经提供了开放下载服务,感兴趣的朋友可以即可去下载安装体验。

