жиИДЪ§ОнЩОГ§ЃКЙЬЖЈКЭПЩБфГЄЖШЪ§ОнПщ
БШЬиЭј ЗЂБэгкЃК12Фъ12дТ26Ше 09:00 [зЊди] БШЬиЭј
1) ЯћГ§Й§аЁПщ
ЯШАДеедЪМЫуЗЈБъЪЖПщБпНчЃЌдйЗДИДКЯВЂаЁгкЛђЕШгкФГИіЯоЖЈжЕLЕФПщЃЌжБЕНЫљгаЕФПщЖМДѓгкLЁЃЪЕМЪгІгУжаЃЌвЛАуЪЧдкchunk sizeЕНДяЯоЖЈжЕLжЎЧАКіТдЕєжИЮЦЁЃ
2) БмУтЙ§ДѓПщ
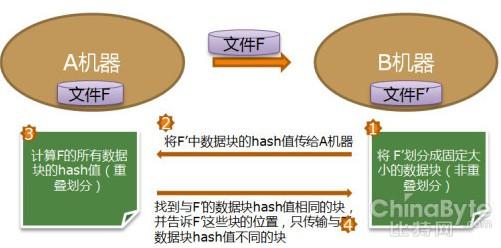
ЯШгУдЪМЫуЗЈБъЪЖПщБпНчЃЌдйНЋДѓгкЯоЖЈжЕTЕФПщЛЎЗжГЩnИіЕШгкTЕФПщЃЌзюКѓФЧПщПЩФмаЁгкЕШгкTЁЃШБЕуЪЧЖдгкДѓПщЃЌжиИДСЫЙЬЖЈЗжПщЕФШБЕуЃКдкПщЭЗВПФГИіЮЛжУВхШызжНкЛсдьГЩећИіПщhashжЕЕФИФБфЃЌЦфЪЕПщжаДѓВПЗжФкШнЪЧБЃГжВЛБфЕФЁЃ
3) ЫЋЛЎЗжвђзг
гУСНИіDЕФжЕЃКУПДЮМЦЫуDКЭD'(Р§ШчD'=D/2)СНЬзжИеыЃЌШєевЕНСЫD'-matchЃЌВЛТэЩЯЛЎЗжЮЊПщБпНчЃЌЯШМЧТМЯТРДЁЃШчЙћD- matchдкЩшЖЈЕФTmaxжЎЧАгаСЫЃЌОЭгУD-matchЃЌШєЕНСЫTmaxЛЙУЛгаЃЌОЭПДжЎЧАгаD'-matchЗёЃЌгаОЭгУD'-matchЛЎЗжЃЌУЛгаОЭгУ TmaxЁЃ
4) ЫЋБпНчЃЌЫЋЛЎЗжвђзг
НсКЯвдЩЯШ§жжЗНЗЈЁЃ
u A low-bandwidth network file system
Muthitacharoen A, Chen B, Maziéres D. In: Proc. of the 18th ACM Symp. on Operating System Principles (SOSP 2001). New York: ACM Press, 2001. 174−187.
LBFSЪЧгЩMITПЊЗЂЕФвЛПюЭјТчЮФМўЯЕЭГЃЌФПБъдкгкМѕЩйДЋЪфДјПэЃЌДЋЪфжЎЧАХаЖЯЪ§ОнПщЪЧЗёвбОдкФПБъЛњЦїЩЯДцдкЃЌШчЙћДцдкдђВЛгУЗЂЫЭЪ§ОнПщЁЃСэ ЭтЃЌLBFSгУSHA-1жЕЕФЧА64ЮЊзїПщЫїв§ЃЌгаГхЭЛЕФПЩФмадЁЃИќаТВЩгУЗЧЭЌВНЗНЪНЃЌЗўЮёЦїЖЫЯШгІД№ПЭЛЇЖЫЃЌдкИќаТЪ§ОнПтЁЃЫљвдLBFSЪЙгУЪ§ОнПтЙмРэ ПщЕФhashжЕЃЌЕЋВЂВЛвРРЕгкЪ§ОнПтЁЃЗўЮёЦїЖЫгыПЭЛЇЖЫЙВЯэЯрЭЌЕФЪ§ОнПтЫїв§КХЁЃLBFSЕФdedupeжївЊЙЄзїдРэШчЯТЭМЫљЪОЃК
LBFSЕФЯджјгХЕуЪЧвЛДЮжЛашвЊПМТЧСНИіЮФМўЃЌЗНБуПьЫй;ШБЕуЪЧвЛИіЮФМўЕФжиИДЪ§ОнПЩФмЗжВМдкЖрИіЮФМўжаЃЌетбљЕФЗНЗЈФмМьВтЕНЕФжиИДЪ§ОнЗЧГЃгаЯоЁЃ LBFSвВЭЌЩЯУцвЛбљЃЌЮЊЗРжЙЗжПщжаЕФМЋЖЫЯжЯѓЃЌЩшжУСЫПщДѓаЁЕФзюДѓЁЂзюаЁжЕЁЃдкLBFSЕФВтЪдЪ§ОнжаЃЌЛЌЖЏДАПкДѓаЁЪТ48bytesЃЌЦНОљПщДѓаЁЮЊ 8KBЃЌзюаЁЕФПщЮЊ2KBЃЌзюДѓПщЮЊ64KBЁЃ



