жиИДЪ§ОнЩОГ§ЃКЙЬЖЈКЭПЩБфГЄЖШЪ§ОнПщ
БШЬиЭј ЗЂБэгкЃК12Фъ12дТ26Ше 09:00 [зЊди] БШЬиЭј
1.2.2 ПЩБфДѓаЁЪ§ОнПщ(ЛљгкЮФМўФкШнЕФВщев)
ПЩБфДѓаЁЪ§ОнПщЕФМьВтЪЧЛљгкЮФМўФкШнЕФНЋЮФМўЗжГЩДѓаЁВЛЕШЕФЪ§ОнПщЃЌЭЈГЃЪЧРћгУRabinжИЮЦЕФЗНЗЈМЦЫуГіЪ§ОнФкШнЕФжИЮЦжЕЁЃRabinжИЮЦЪЧвЛжжИпаЇЕФжИЮЦМЦЫуКЏЪ§ЃЌРћгУhashКЏЪ§ЕФЫцЛњадЃЌЫќЖдШЮвтЪ§ОнЕФМЦЫуНсЙћБэЯжГіОљдШЗжВМЁЃЛљгкФкШнЕФЪ§ОнПщЛЎЗжЗНЗЈШчЯТЃК
дЄЯШЩшЖЈвЛЖдећЪ§DЃЌr(D>r)КЭвЛИіЛЌЖЏДАПкЕФЙЬЖЈПэЖШl(ЪЕМЪжаГЃгУr=D-1)ЁЃЖдгквЛИіађСаS=S1,S2,……,SnЃЌЕБЧвНіЕБ ДАПкЕФБпдЕЭЃдкФГвЛИіkЮЛжУЃЌвВОЭЪЧзгађСаW=S(k-l+1),S(k-l+2),……,SkЕФжИЮЦКЏЪ§МЦЫуНсЙћЮЊh(W) mod D = rЃЌдђkЮЛжУгавЛИіD-matchЁЃkЮЛжУвВОЭЪЧФГИіЪ§ОнПщЕФБпНчЮЛжУЁЃ
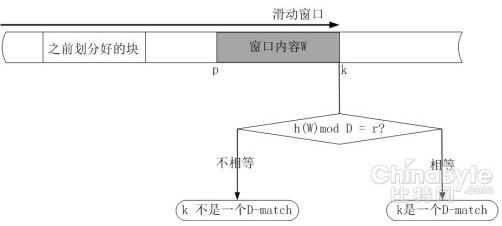
ЪЕМЪВйзїЪБЃЌДгЮФМўЭЗВППЊЪМЃЌНЋЙЬЖЈДѓаЁ(ЯрЛЅжиЕў)ЕФЛЌЖЏДАПкжаЕФЪ§ОнзїЮЊRabin жИЮЦЕФзгађСаЃЌМЦЫуУПИіДАПкЮЛжУЕФжИЮЦЁЃЕБТњзужИЮЦЬѕМўЪБЃЌОЭНЋДЫЪБДАПкЫљдкЮЛжУЕФБпНчзїЮЊПщЕФБпНчЁЃжиИДетбљвЛИіЙ§ГЬЃЌжБЕНећИіЮФМўЪ§ОнЖМБЛЛЎЗжГЩЪ§ОнПщЁЃНгЯТРДдйгУhash КЏЪ§(MD5 ЛђепSHA) МЦЫуГіУПИіЛЎЗжЕФЪ§ОнПщhash жЕЃЌВЂНЋЫќУЧЙмРэЦ№РДДцЗХдкhash КЏЪ§жЕПтжаЁЃгааТРДЕФЮФМўЪБЃЌЪзЯШАДееЩЯЪіЗНЗЈЛЎЗжГЩЪ§ОнПщЃЌдйНЋУПИіЪ§ОнПщЕФhash жЕгывбДцДЂЕФЪ§ОнПщhash жЕНјааЖдБШЃЌШчЙћМьВтЕНЯрЭЌЕФhash жЕЃЌдђВЛДцДЂЦфДњБэЕФЪ§ОнПщЃЌЗёдђДцДЂетИіаТЪ§ОнПщВЂИќаТhash жЕПтаХЯЂЁЃШчЭМЫљЪОЃК
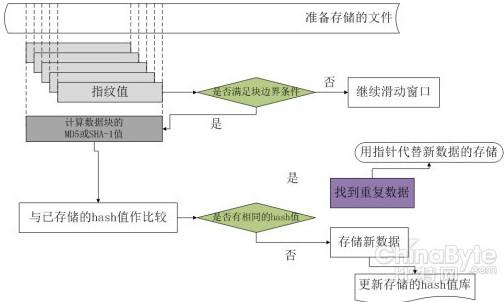
РћгУЛљгкЮФМўФкШнЕФЛЎЗжЗНЗЈЃЌЮоТлЪЧВхШыЛЙЪЧЩОГ§вЛаЁВПЗжзжНкЃЌЖМжЛЛсгАЯьЕНвЛЕНСНИіПщЃЌЦфгрЕФПщБЃГжВЛБфЃЌЫљвдЖдгкжЛЯрВюМИИізжНкЕФЪ§ОнПщПЩвдМьВтГіИќЖрЕФШпгрЁЃ
ОЕфЮФЯз
u A Framework for Analyzing and Improving Content-Based Chunking Algorithms
K.Eshghi and H. K. Tang. Technical Report HPL-2005-30(R.l), Hewlett Packard Laboraties, Palo Alto, 2005.
ЩЯУцУшЪіЕФЪ§ОнПщЛЎЗжЗНЗЈШнвзВњЩњвЛаЉЮЪЬтЁЃгЩгкhashКЏЪ§ЕФЫцЛњадЃЌМЋЖЫЧщПіОЭЪЧФГЮФМўЪМжеевВЛЕНD-matchЃЌдьГЩЪ§ОнПщЙ§Дѓ(ПЩФмЪЧвЛИі ЮФМўжЛгавЛИіЪ§ОнПщ);СэвЛИіМЋЖЫЧщПіОЭЪЧУПИізжНкЖМЪЧD-matchЃЌетбљЪ§ОнПщЙ§аЁ(жЛга1зжНкЕФГЄЖШ)ЁЃеыЖдетаЉПЩФмГіЯжЕФЮЪЬтЃЌБОЮФЬсГіСЫвЛаЉИФ НјЫуЗЈЃЌВЂЧвИјГіСЫШчКЮЦРЙРетаЉЫуЗЈКУЛЕЕФЪ§бЇЙЋЪНЁЃжївЊЕФИФНјЫуЗЈШчЯТЃК



