FacebookЕФHadoopгІгУгыЙЪеЯзЊвЦЗНАИ
ДѓЪ§ОнММЪѕгыЪЕеН ЗЂБэгкЃК12Фъ07дТ04Ше 14:23 [зЊди] IT168
ЮвУЧдјЬсЕНЙ§дкЖЬЖЬЕФ60УыФкЃЌFacebookЕФгУЛЇЛсЗжЯэ684478ЬѕаХЯЂЃЌLikeАДХЅБЛЕуЛї34772ДЮЁЃХгДѓЕФвЕЮёСПЪБПЬПМбщзХ FacebookЕФЪ§ОнДІРэФмСІЁЃЮвУЧжЊЕРЃЌFacebookЪЙгУHadoopРДНјааДѓЪ§ОнЕФДІРэЃЌЕЋFacebookгжЪЧШчКЮБЃеЯЦЕЗБЁЂХгДѓЕФЪ§ОнЧыЧѓЕШИпбЙЛЗОГЯТВЛЗЂЩњЙЪеЯЕФФи?ЮвУЧвЛЦ№РДСЫНтвЛЯТFacebookФкВПЕФHadoopЪЙгУЧщПівдМАЦфNameNodeЙЪеЯзЊвЦММЪѕЁЃ
Facebook HadoopМЏШКФкФПЧАЕФHDFSЮяРэДХХЬПеМфГадиГЌЙ§100PBЕФЪ§Он(ЗжВМдкВЛЭЌЪ§ОнжааФЕФ100ЖрИіМЏШК)ЁЃгЩгкHDFSДцДЂзХHadoopгІгУашвЊДІРэЕФЪ§ОнЃЌвђДЫгХЛЏHDFSГЩЮЊFacebookЮЊгУЛЇЬсЙЉИпаЇЁЂПЩППЗўЮёжСЙиживЊЕФвђЫиЁЃ
HDFS NamenodeЪЧШчКЮЙЄзїЕФ?
HDFSПЭЛЇЖЫЭЈЙ§БЛГЦжЎЮЊNamenodeЕЅЗўЮёЦїНкЕужДааЮФМўЯЕЭГдЪ§ОнВйзїЃЌЭЌЪБDataNodeЛсгыЦфЫћDataNodeНјааЭЈаХВЂИДжЦЪ§ОнПщвдЪЕЯжШпгрЃЌетбљЕЅвЛЕФDataNodeЫ№ЛЕВЛЛсЕМжТМЏШКЕФЪ§ОнЖЊЪЇЁЃ
ЕЋNameNodeГіЯжЙЪеЯЕФЫ№ЪЇШЗЪЧЮоЗЈШнШЬЕФЁЃNameNodeжївЊжАд№ЪЧИњзйЮФМўШчКЮБЛЗжИюГЩЮФМўПщЁЂЮФМўПщгжБЛФФаЉНкЕуДцДЂЃЌвдМАЗжВМЪНЮФМўЯЕЭГЕФећЬхдЫаазДЬЌЪЧЗёе§ГЃЕШЁЃЕЋШчЙћNameNodeНкЕуЭЃжЙдЫааЕФЛАНЋЛсЕМжТЪ§ОнНкЕуЮоЗЈЭЈаХЃЌПЭЛЇЖЫЮоЗЈЖСШЁКЭаДШыЪ§ОнЕНHDFSЃЌЪЕМЪЩЯетвВНЋЕМжТећИіЯЕЭГЭЃжЙЙЄзїЁЃ
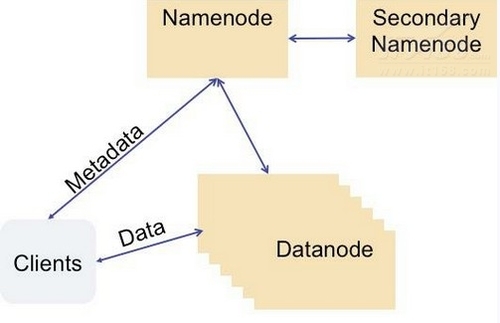
ЁјThe HDFS Namenode is a single point of failure (SPOF)
FacebookвВЩюжЊ“Namenode-as-SPOF”ЫљДјРДЮЪЬтЕФбЯжиадЃЌЫљвдFacebookЯЃЭћНЈСЂвЛЬзЯЕЭГвбЦЦГ§“Namenode- as-SPOF”ДјРДЕФвўЛМЁЃЕЋдкСЫНтетЬзЯЕЭГжЎЧАЃЌЪзЯШРДПДвЛЯТFacebookдкЪЙгУКЭВПЪ№HDFSЖМгіЕНСЫФФаЉЮЪЬтЁЃ



