

德国汉堡ISC 2026 IO500榜单发布,中科曙光团队及相关代表合影留念
6月24日,在德国汉堡举办的ISC 2026高性能计算大会期间,最新IO500榜单发布。中科曙光分布式全闪存储ParaStor F9000在生产型全节点榜单和10节点榜单中均获得第一。
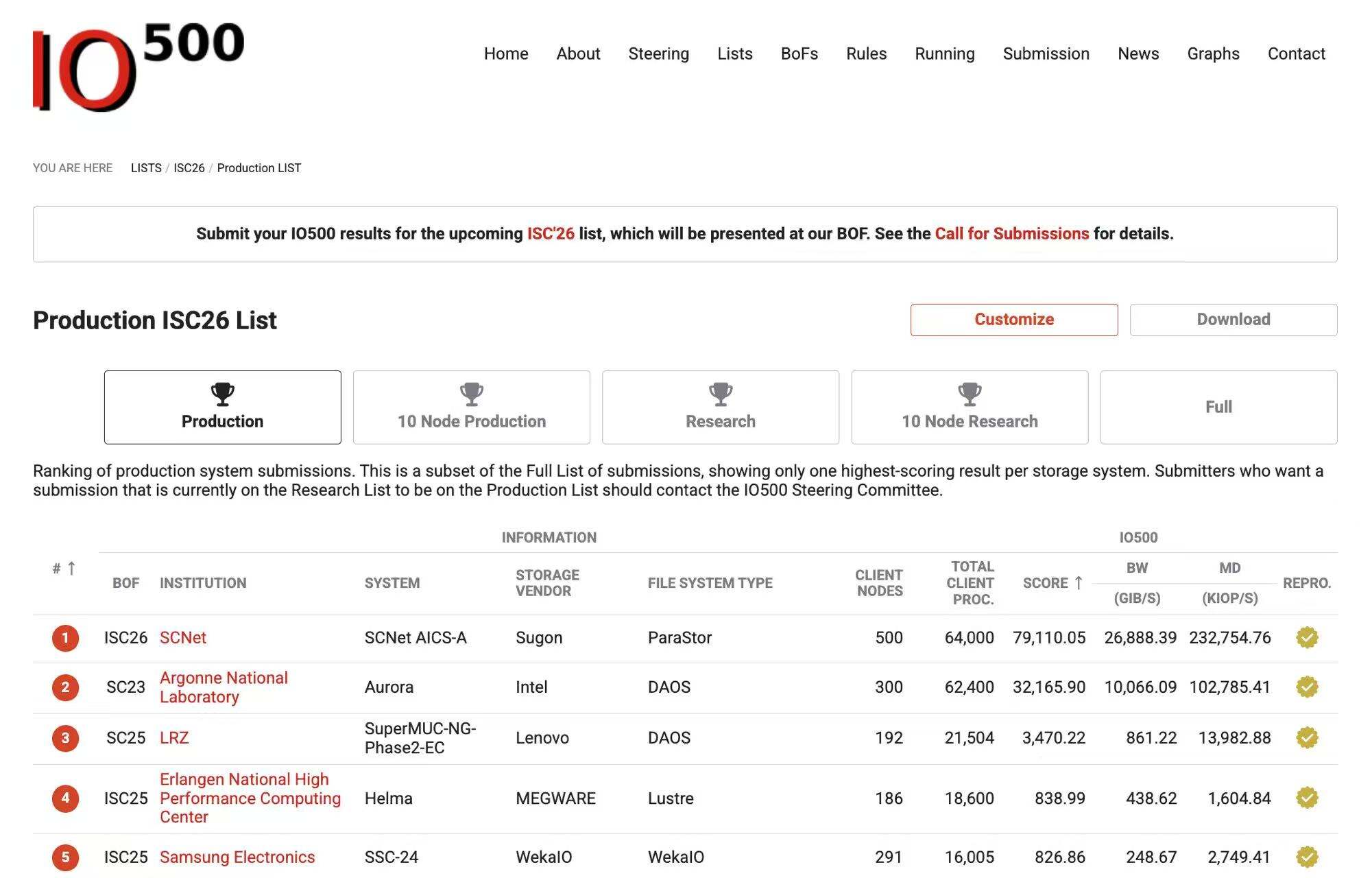
IO500生产型全节点榜单第一
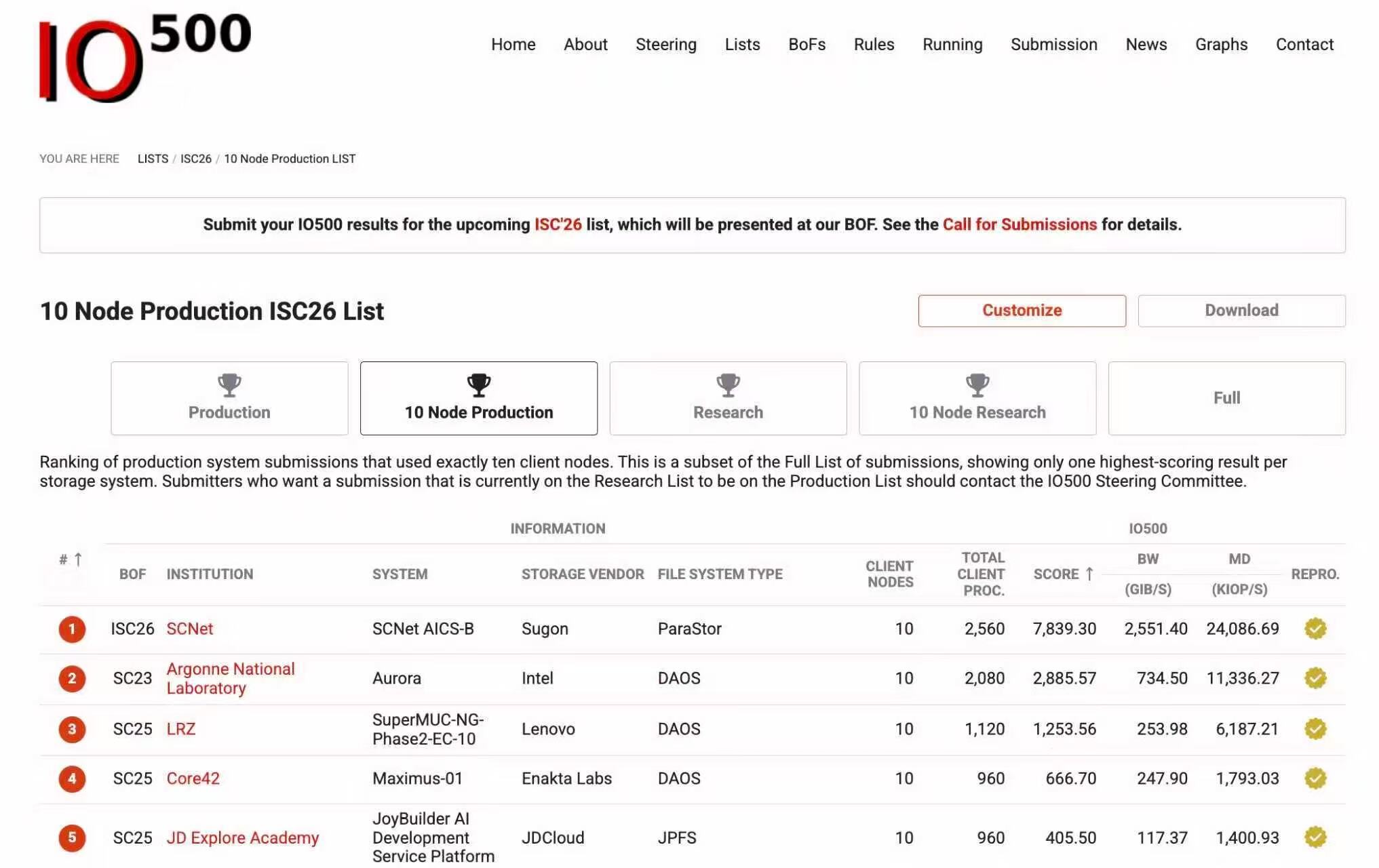
IO500生产型10节点榜单第一
这是中国企业首次在生产型双榜上同时登顶,代表着国产高端存储首次在这一更贴近真实生产环境的国际评测体系中完成了全规模验证。
10节点和全节点生产型榜单强调真实部署、真实负载和长期运行环境,与研究型榜单不同,参选门槛更高,要求设备真实运行时间在一年以上。其含金量不言而喻——既要在小规模高密度场景中释放极致性能,又要在更大规模完整集群中保持性能一致性和稳定性。这比单点跑出高峰值更难,也更能证明系统工程能力。
IO500生产型榜单“考”什么?
首先要了解,IO500是高性能计算领域最具影响力的存储排行榜之一。对应衡量超级计算系统算力水平的TOP500,IO500更关注存储系统在高性能计算、科学计算和数据密集型业务中的整体表现,从系统角度考察存储软硬件整体能力。
IO500榜单又分为生产型与研究型。二者在测试规则上存在显著差异:生产型榜单严禁使用影响结果的缓存/预热,需基于实际后端存储运行,必须保障数据持久化与容错能力,且环境需稳定可复现,贴近真实业务场景。
研究型榜单则允许使用内存盘加速、自定义测试工具(如pfind)、关闭数据保护机制,甚至可在不稳定环境中测试,旨在挖掘存储架构的理论性能极限。
相比之下,研究型榜单侧重特定测试条件下的性能验证,而生产型榜单更强调真实业务场景下的实战检验。
生产型10节点与全节点榜单,其背后的挑战又有所不同。
10节点榜单更像是对存储系统极限释放能力的考验。在有限的10个客户端节点下,系统要尽可能释放计算节点与存储节点之间的数据通路能力,核心指标集中在集群带宽和元数据访问性能上。
带宽和元数据性能对系统产生压力的方式不一样。大带宽顺序I/O需要存储系统持续、稳定地搬运大量数据。元数据访问则更考验小I/O、目录、文件创建、查询和管理能力。
前者像高速公路上持续跑重载货车,后者像城市路面上的大量短途、高频、随机流动汽车。要在同一套存储底座上同时做好这两件事,要具备极强I/O调度、资源分配和负载平衡能力。
全节点榜单则进一步考验完整集群下的长期稳定运行能力,不仅要求带宽和元数据性能,还要掌控每次I/O流向,确保长时间混合负载下的运行稳定性,不出现性能衰减、抖动和局部瓶颈。
中科曙光北京公司总裁助理、分布式存储产品部总经理石静在采访中谈到,这类评测不是脱离业务单独优化,是在应用叠加、业务持续运行的情况下接受检验。也就是说,存储系统既要服务现有业务,又要承受评测负载,对混合负载下的性能隔离、QoS管理和资源调度提出更高的要求。
生产型双榜第一背后,是软硬件的系统协同
中科曙光ParaStor F9000的生产型双榜第一,不是单纯依赖NVMe SSD本身的性能。全闪介质只是基础,真正决定系统上限的,是软硬件以及网络互联能力的相互协同。
在硬件设计上,ParaStor F9000采用2U2N分布式存储架构。与市面常见的2U24盘位设计不同,2U2N是在2U空间集成两个物理节点,每个节点拥有独立主板、CPU、内存、网卡和SSD。这种号称“双子星”的结构能在有限空间内提高节点密度,同时让每个节点围绕CPU形成更短、更均衡的数据通路,减少中间转发和资源争用,提升性能释放效率。
ParaStor F9000在SSD与网卡连接上强调直连CPU,避免通过PCIe Switch产生额外转发与资源竞争。读数据时,数据从NVMe SSD进入CPU,再经网卡发出到计算节点;写数据时,数据从网卡进入,再下刷到SSD。如果硬件拓扑设计不合理,就容易在PCIe通路、CPU核心、内存访问和网卡之间形成瓶颈。
这也是中科曙光分布式存储总工程师袁清波强调网络和NVMe重新排布的原因。ParaStor F9000是让每一次I/O从发起时就被安排好通路——走哪个网卡、用哪个CPU核、访问哪段内存、最终落到哪块后端盘。只有把数据路径规划到足够清晰、稳定和可控,硬件性能才能真正释放出来。
网络互联是非常关键的一环。ParaStor F9000采用的是曙光自研,面向大规模AI计算集群推出的scaleFabric原生无损RDMA高速网络。其定位是面向万卡、十万卡级智算和高性能集群的数据互联需求,具备高带宽、低时延和无损传输特性。
还有软件层面,把CPU核进行虚拟化处理,内存也进行虚拟化切分,然后把每一个CPU对应的内存、网络和SSD组成一个小型专速的超级公路,让每笔IO在对应的网卡、内存上进行传输,并确保两笔通信IO相互不影响,同样是做到资源调度的精细化。
从IO500到AI生产系统,存储价值前移
ParaStor F9000登顶IO500生产型双榜,首先验证的是高性能存储系统能力。如今,AI正在重新定义数据基础设施的重要性,比如大模型训练需要持续读取海量训练数据,推理要处理长上下文、多轮对话和高并发请求带来的压力。
围绕AI生产场景,中科曙光也在持续扩展ParaStor的能力。其中,一个典型方向,是面向大模型长上下文推理的原生KV Cache智能卸载能力。
在大模型推理过程中,系统会把已经计算过的上下文信息缓存下来,形成 KV Cache,避免后续生成时反复计算前文内容。随着上下文长度、多轮对话增加以及高并发请求,KV Cache会快速占用GPU显存,进而限制单卡并发能力和长上下文处理能力。
ParaStor的思路是把存储纳入推理过程的数据调度链路中,系统可识别GPU显存里暂时闲置、访问频率较低的KV Cache块,并将其动态迁移到后端高性能全闪存储中。当推理过程再次需要相关上下文时,再通过XDS高速通路直接回传到显存,在显存占用、访问时延和系统成本之间取得平衡。
总结:双榜第一,是一次全球能力验证
ParaStor F9000登顶IO500 生产型双榜,验证的是介质、节点架构、无损网络、软件调度、QoS和数据路径编排共同形成的系统能力。
正如中科曙光北京公司副总裁何振所言,这次成绩的价值不在于“两个第一”本身,而在于它是在IO500最贴近真实业务环境的评测体系中完成的全规模验证。
我印象比较深刻的是,大家反复提到的要把发出的每一次I/O路径都安排得清清楚楚。这个工程细节背后是中科曙光持续多年的工程积累和技术创新。ParaStor F9000登顶IO500生产型双榜,是全球测评体系对这种系统能力的一次严格“审计”。对国产高端存储而言,这也是从“可用”走向“可竞争”的关键一步。
