
短短9个月,存储市场的焦点已从“如何卖出产品”的内卷,转向了头部客户“抢购”带来的供应挑战。在2026人工智能基础设施峰会上,联想凌拓首席技术官陈弘深入剖析了AI为存储市场带来的变化,也分享了对于存储未来的洞察。

陈弘以“帮助客户加速全面AI-Ready,构建决定AI项目成败的关键基础设施”为核心,系统阐述了一位存储从业者面对AI时代的思考、涵盖了潜在的机遇与落地路径。
企业的AI转型,需要真正专属的数据底座
陈弘首先指出,企业落地AI时,在存储系统层面面临的四个具体痛点。
第一,数据孤岛,这是AI落地的起点难题。
企业长期建设过程中,数据分散在不同部门、系统和存储类型中,形成孤岛,各自独立运转。这种模式在传统业务中或许尚可勉强运转,但在AI场景下则成为明显障碍。
第二,数据流转:算力之后的新瓶颈。
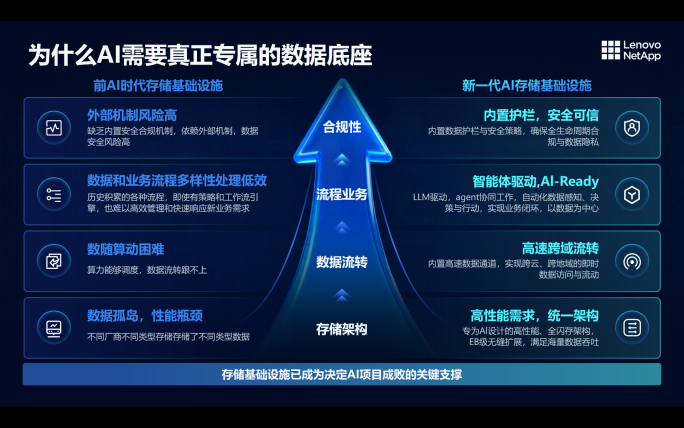
当前算力调度已经相对成熟,但数据无法高效流动,成为新的卡点。现实中,数据流转瓶颈常因算力与数据分布不均、存储资源不足或扩展滞后,以及当数据需要跨机房、跨云的数据调度时产生。这导致算力就位后,数据迟迟跟不上。
第三,数据与业务多样性:AI转型的复杂性来源
企业内部往往存在大量业务系统,每个系统都有自己的数据结构和使用方式。而AI项目通常是公司级工程,需要打通多个业务条线。但由于缺少统一的数据架构,不同数据格式、接口、语义无法统一,导致数据从原有业务流程接入AI变得很困难。
第四,安全与合规:决定AI能否真正落地
相比技术实现,安全与合规往往更复杂、更耗时。如今的企业普遍关注几个话题,比如,数据是否上云、是否出域、在推理过程中数据是否会被模型学习、是否存在知识产权泄露风险,这不仅是技术问题,还涉及法务、安全、监管等各方面,非常复杂。
联想凌拓对未来存储的三层设想
谈及应对之策,陈弘提到了以数据为中心的新一代全景架构,并系统阐述了联想凌拓对未来存储的三层设想。
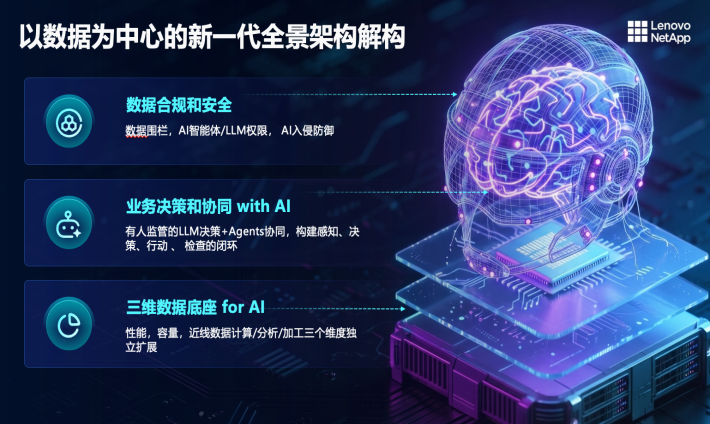
第一层是数据底座。除了性能和容量,未来的存储底座还需要加一个数据加工能力。之前存储行业遵循一个原则:不碰客户数据。这在传统时代没问题,但到了AI时代,客户不只是需要获取裸数据,而是希望存储厂商能够处理数据,提供面向AI-Ready的数据。
陈弘用了一个形象的比喻:存储以前是“菜农”,提供从地里采摘的原始食材(裸数据)。现在则要提供“净菜”甚至“预制菜”(经初步加工、面向AI-Ready的数据),让客户不需要在计算层重新处理数据。换句话说,存储系统本身要具备就近的数据加工处理能力。
第二层,存储系统的交互方式需要从UI(用户界面)变成Storage Agent(存储智能体)。传统存储提供的是面向管理员的交互界面。而当越来越多系统由大模型决策、Agent协同,那么存储本身也需要变成一个能跟AI系统无缝对接的Agent,而不仅是只有图形界面。
第三层,AI时代的数据围栏要升级。传统存储防病毒、防勒索,权限管理是基于人的。但大模型和智能体介入后,哪些数据可以给大模型看,哪些数据可以给某个智能体访问,都得定义清楚。
陈弘举了一个生动的例子:“不能因为有人向大模型随口一问,就获得CEO的工资单。数据权限机制必须跟上AI的使用方式。”
NetApp AFX+AIDE:计算存储分离三层架构
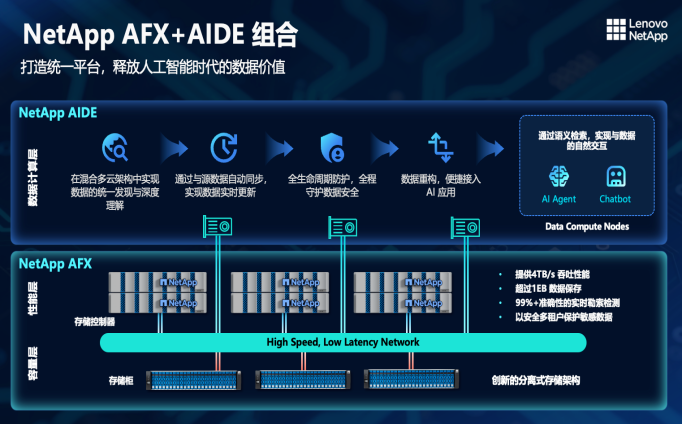
基于这样的设想,联想凌拓针对AI场景推出了NetApp AFX + AIDE的组合方案,通过构建一个统一的存储+数据平台,释放人工智能基础设施中的数据价值。这套方案的核心理念是将计算和存储分离,具体可以拆成三层:
最底层是容量层,把高性能存储盘柜和原来的集中式存储控制器解耦,既能横向扩展容量,也能纵向扩展。
中间是控制层,这层其实更像协议层,负责给客户提供高性能的数据接入。这两层都是NetApp AFX存储系统的职责范围。
最上层是AIDE数据引擎节点,叫做数据计算层,专门负责就近数据计算和智能处理。这一层的核心用途是数据加工,而不是存数据。当用户对数据的加工能力要求更高时,就需要用到这一层。
值得注意的是,AIDE不是传统的外挂式的数据管理平台,而是AFX集群的一部分。在同一个AFX集群里,有的节点扮演容量角色,有的扮演控制和协议角色,AIDE节点扮演就近计算角色,三层都可以独立横向扩展。
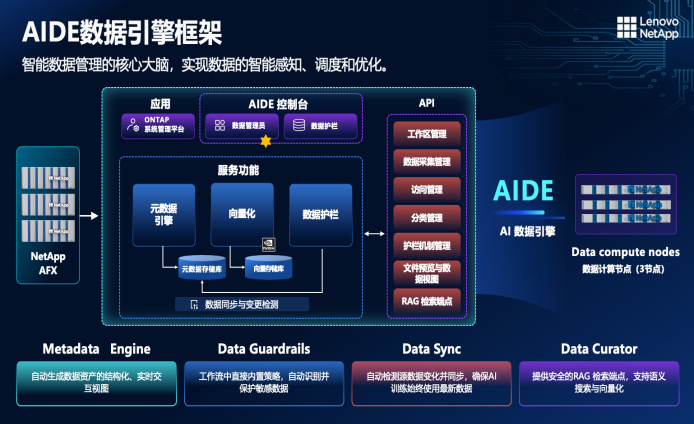
AIDE的元数据引擎(Metadata Engine)管理的不是存储数据的元数据,而是与客户业务数据的元数据。数据喂给AI系统之前要做标注、清洗、数据围栏分离,这些都跟业务工作流紧密绑定。
在AIDE里,还通过Data Guardrails实现授权和访问权限的管理, Data Sync则负责按需数据流转,它不是整体搬迁数据,而是按需把数据给到计算节点。此外, Data Curator还会对异构存储做统一视图和统一访问。
联想存储智能体:从规则引擎到可以自学习的智能体
除了基础架构,陈弘还分享了联想存储智能体(LiSA)这一前沿技术,它将彻底改变存储的管理和使用方式。这部分内容尤为有趣,它可以与前文提到的AIDE数据引擎配合使用。
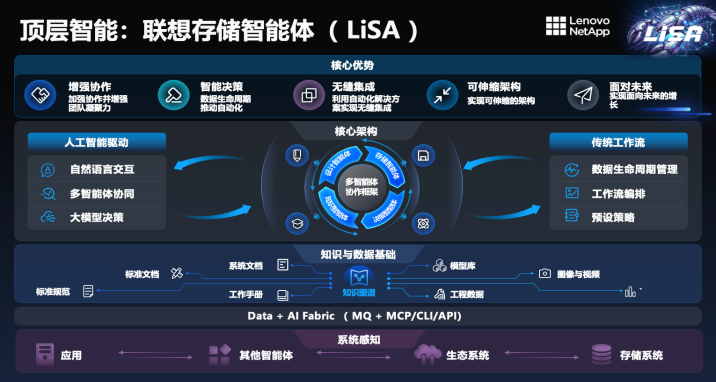
LiSA最初就是为了帮助客户对大量异构存储做数据拉通,让数据跟随业务流转。只不过,当时用的是规则驱动的自动化系统,每个业务流都可以按照客户要求按策略定制,显然,这种模式不方便大规模复制。
去年,联想凌拓在原有系统上引入大模型与智能体框架。这使得系统从执行预设流程,转变为能够“自主进化”——可以根据客户需求,自行衍生出所需的工作流程。
这一转型为何能够实现?陈弘揭示了关键的底层能力——“Data + AI Fabric”。传统Data Fabric专注于数据层面的流转,而新增的AI Fabric具备了与大模型、AI Agent互动的机制。在这里就不得不提到MCP了。
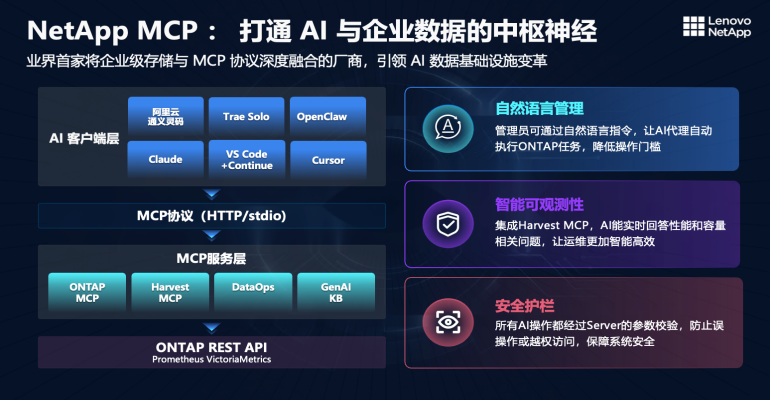
关于NetApp在MCP生态上的布局,陈弘表示,NetApp基于丰富的CLI、API,构建了一整套开源的MCP服务体系,包括负责资源管理的ONTAP MCP、负责监控分析的Harvest MCP,还有围绕企业数据运营和知识库生成的DataOps MCP和GenAI KB MCP。
陈弘还提到了一个值得关注的现象:头部厂商的大模型对NetApp的产品文档和 API都非常熟悉,基于这些模型开发NetApp AI应用的时候,通常无需再进行额外训练,模型似乎已掌握了必要的知识。
AI赋能存储专家,释放更高阶业务价值
陈弘最后分享了三个联想凌拓内部的实践案例,有力印证了上述的趋势。
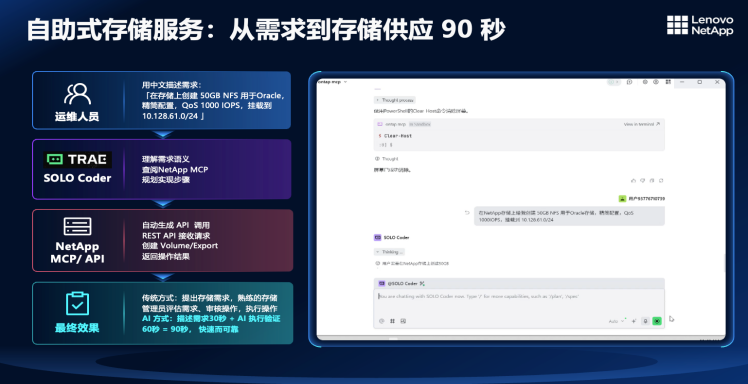
第一个是用自然语言管理存储。客户想在NetApp存储上创建一个50GB的NFS给Oracle系统用。传统模式下,管理员要查阅厚厚的手册,谨慎地执行命令。而现在,只需要用自然语言向AI说出需求,系统就可以自动创建存储并完成挂载,并生成一份总结报告。
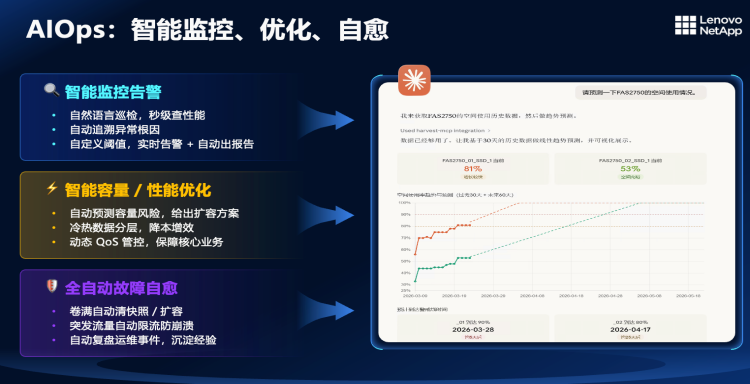
第二个案例是联想凌拓解决方案架构师利用AI工具。开发了一套具备智能容量预测、性能优化、全自动故障报警的能力的AIOps工具。陈弘表示,存储容量预测这项工作原来对产品研发来说需要不小的工程量,这位解决方案的架构师一个周末就搞定了。

第三个案例则更进一步,展示了销售同事利用AI开发的演示工具。为了提升向客户介绍方案的效果,他利用业余时间,借助AI编程结合NetApp的AI能力搭了一系列演示场景,向用户直观展示跨站点容灾、防勒索等高级技术,改变了以前存储销售宣讲只说不做的不直观的问题。这些演示对应的用户界面原本需要研发团队很长的开发周期才能实现,作为演示目的来说太慢了。
这三个案例让我们清晰地认识到,AI确实在把原本需要专业人员花很长时间才能做到的事情,让非技术人员也能快速完成。当然,想做到这些,除了会使用AI技术,还得让存储产品本身具备AI能力,否则这一模式将难以实现。
结束语
近两年来,AI行业的重点正从训练转向推理,存储从业者正紧盯推理场景寻找机会。不久前,NVIDIA CEO黄仁勋表示,推理可以靠STX和CMX解决,可以把存储直接置于GPU服务器内,回到DAS模式时,传统存储厂商的角色似乎变得模糊。
但陈弘认为,存储厂商的目光应超越推理本身,溯游至数据的上游——专注于数据加工、AI Agent接口与企业级数据治理。这些领域正是数据价值释放的核心,也恰恰是传统存储厂商凭借其深厚积淀,最能创造独特优势的业务领域。
NetApp在MCP生态上的铺垫,可能是目前国际存储厂商最激进的尝试之一。一旦此类生态成熟,必将重塑企业存储的运维模式。这或许是存储厂商在AI时代构建核心竞争力的关键。



