
4月17日,在DOIT传媒主办的2026人工智能基础设施峰会上,浪潮数据云存储营销总监张业兴做了一场题为《融存智用 运筹新数据》的分享。

说实话,存储厂商讲存储主题我听过不少,大部分都是产品参数和客户案例堆在一起,听完能记住的不多。但张业兴这一场有个判断我觉得挺有意思,他认为智算中心的基本矛盾正在转移,从过去的算力不够用,变成了存力不够用。
这个判断如果成立,那对于整个存储行业,甚至对AI基础设施的建设思路都是一个方向性的变化。所以我想把他讲的内容拆开来聊聊。
AI每进化一次,数据量涨一千倍
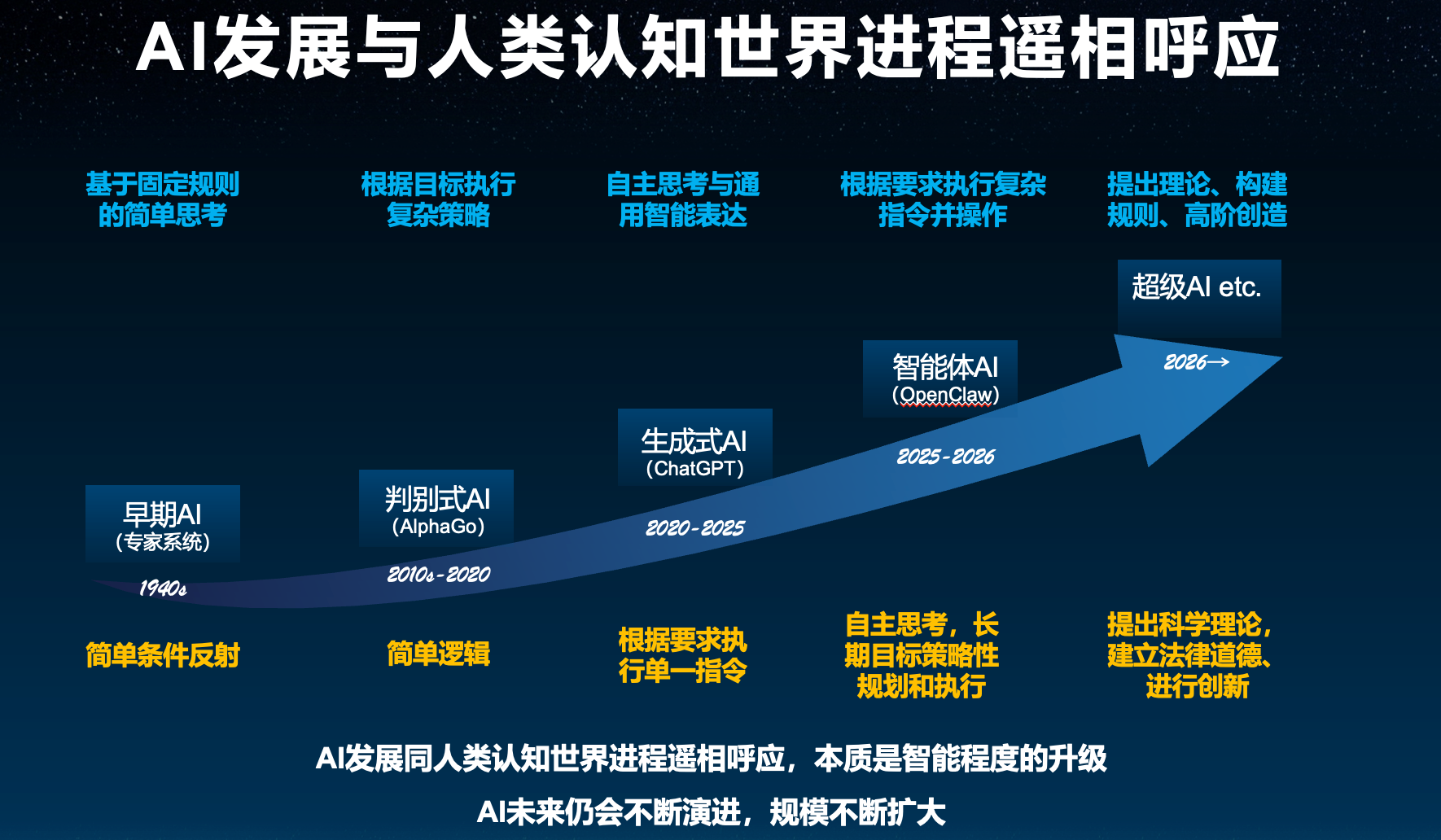
张业兴把AI的发展和人类的认知成长做了类比。上世纪早期的AI是专家系统,基于固定规则运行。深度学习兴起之后,判别式AI成为主流,能做图像、语音识别等判断任务。到了AlphaGo这一代,开始能根据目标执行复杂的策略了。
而到了ChatGPT这一代,生成式AI具备了自主思考和长期规划能力,比如OpenClaw这样的智能体能接收复杂指令并完成一系列操作。他认为,下一阶段的AI可能会具备提出理论、建立规则、进行高阶创造的能力。
这个演进路径跟人类从婴儿到成年的认知发展是对应的。婴儿阶段只有简单的条件反射,随着成长和受教育程度提高,能进行自主思考,能基于目标执行计划。到了工作之后,一部分人甚至能提出科学理论,进行创造性的产出。

生成式AI的早期,智算中心处理数据的规模大概在PB到EB级。而到了Agent阶段,因为需要实时互动、多Agent协同,需要处理的数据量跳到EB到ZB级。在未来的超级AI时代,大模型新产生的数据量会直接到ZB级以上。
张业兴提到,AI每进化一代,数据量会有1000倍左右的跃迁。这是一个挺可怕的增长曲线。按照现在AI的发展速度,在现在这个时点规划的存储容量,放到两三年后可能就完全不够用。
AI时代的算力投资大,但很快存力投资规模将反超算力!
在张业兴分享的折线图中,横轴是时间,纵轴是智算中心里算力和存力的投资金额。在Gen AI阶段,存力增长虽然快,但穷尽整个生命周期可能都追不上算力的原始投资。这也是为什么现在大部分智算中心给人的印象还是以买卡为主。
但到了Agent阶段,情况就变了。因为需要实时互动和协同,存力增长会明显加速,大概在第4到6年的时候,存力投资会追上算力投资。再往后,如果超级AI时代到来,存力增长会更快,存力的投资可能在第2到4年就反超算力投入。
这个预测的方向性非常合理,AI越往智能化方向走,对数据的吞吐、存储、实时调度要求越高,存力的权重一定会持续上升。张业兴认为,随着AI发展,我们的智算中心正在从以算力为中心,转向以存力为中心。
这也是为什么最近这一两年你会看到,过去那些闷声做存储的厂商开始频繁出来讲AI、讲智算中心。不是他们突然想蹭热点,只是因为存储在这一波AI基础设施里的存在感正在快速攀升。
浪潮数据用四个融合,应对AI带来的存储挑战
面对数据预处理阶段,模型训练微调以及推理阶段对存储提出的诸多挑战,张业兴介绍了浪潮数据的融合存储技术战略,分别从介质融合、协议融合、管理融合、应用融合四个层面来应对AI带来的存储挑战。

第一个是介质融合。现在数据中心里的存储介质种类越来越多,DRAM是纳秒级延迟,SSD是毫秒级,磁带是秒级。介质多了之后的问题是,不同热度的数据应该放在不同介质上,但人工配置效率太低,最好是能让系统自己做均衡。
浪潮数据推出了一个智能分层框架来自动做均衡:高性能层构建全闪数据引擎,通过把小的随机IO聚合成大IO,把全闪时延压到微秒级。元数据层做了分区管理和全局负载均衡,能支撑万亿级元数据的有序管理,单节点IOPS到百万级。
冷数据回迁是另一个值得说的点。传统冷热分层最大的痛点就是冷数据回迁慢,用户体验差。浪潮数据的思路是数据归档后保留”元数据存根”,用户端直接访问元数据,系统在后台自动按需回迁,整个过程用户无感知。
测算数据是,如果客户热、温、冷数据比例是10:10:80,整体成本比单一存储架构降低60%以上,能耗降低0.1W/TB。这个比例是非常理想的,虽然并非所有用户数据都是这样的比例,但当用户冷数据多的时候,分层架构的性价比优势会更明显。
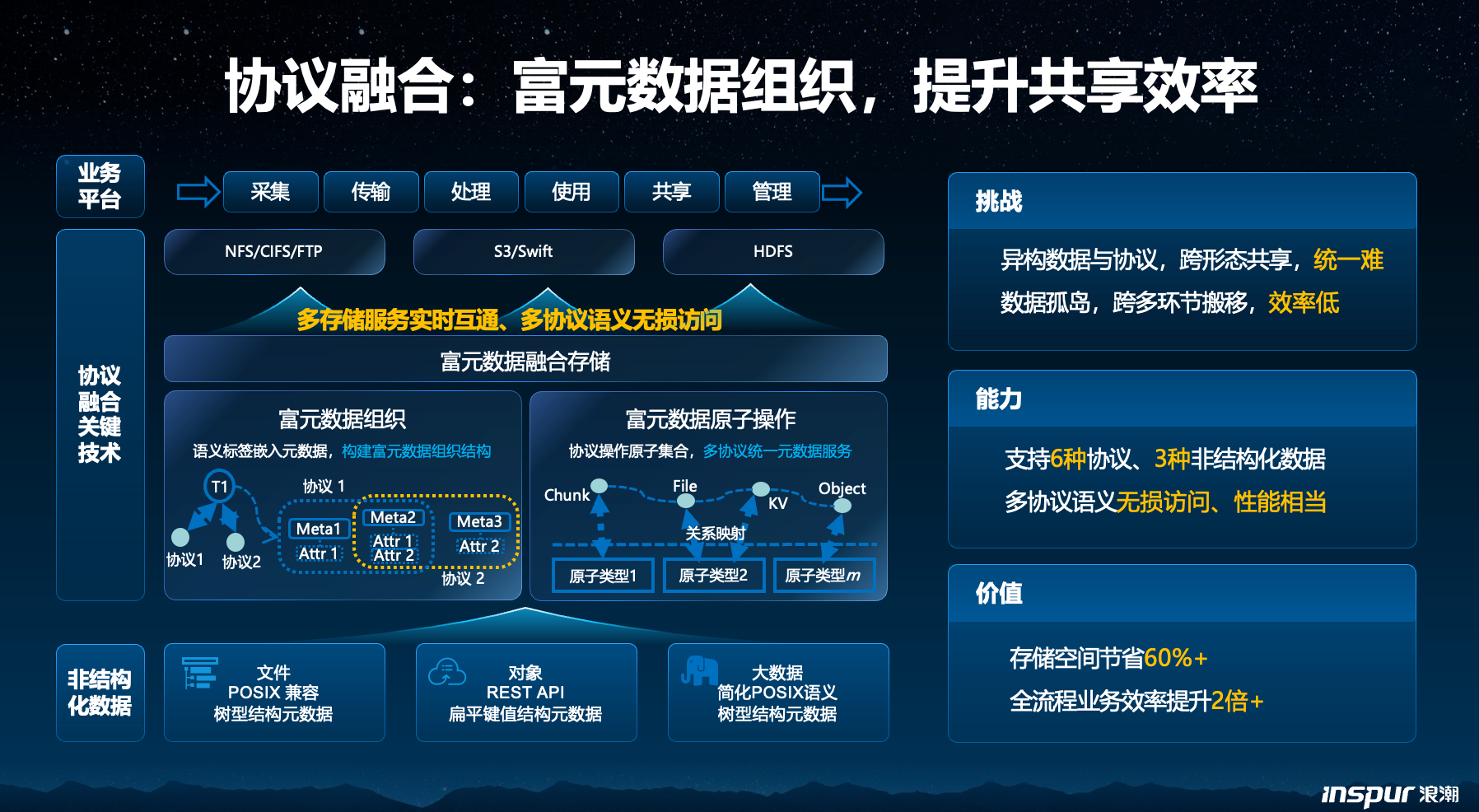
第二个是协议融合。大模型训练的一个现实问题是,数据来源太杂。有文件、有对象、有大数据,每种都有自己的访问协议。跨协议共享很难,业务运转效率上不去。浪潮数据给出的解法叫富元数据融合存储架构,思路分两步:
第一步,给元数据打语义标签,把协议的操作语义和元数据对应起来,构建能支持多种非结构化数据的富元数据结构。第二步,把各协议特有的复杂操作拆解成一套标准化的原子操作集,所有协议的元数据操作都映射进来,对外提供统一的元数据服务。
浪潮数据官方结果显示,经过这么一番操作下来,不仅实现了多协议语义无损访问,还将多类型数据的存储空间节省了60%。
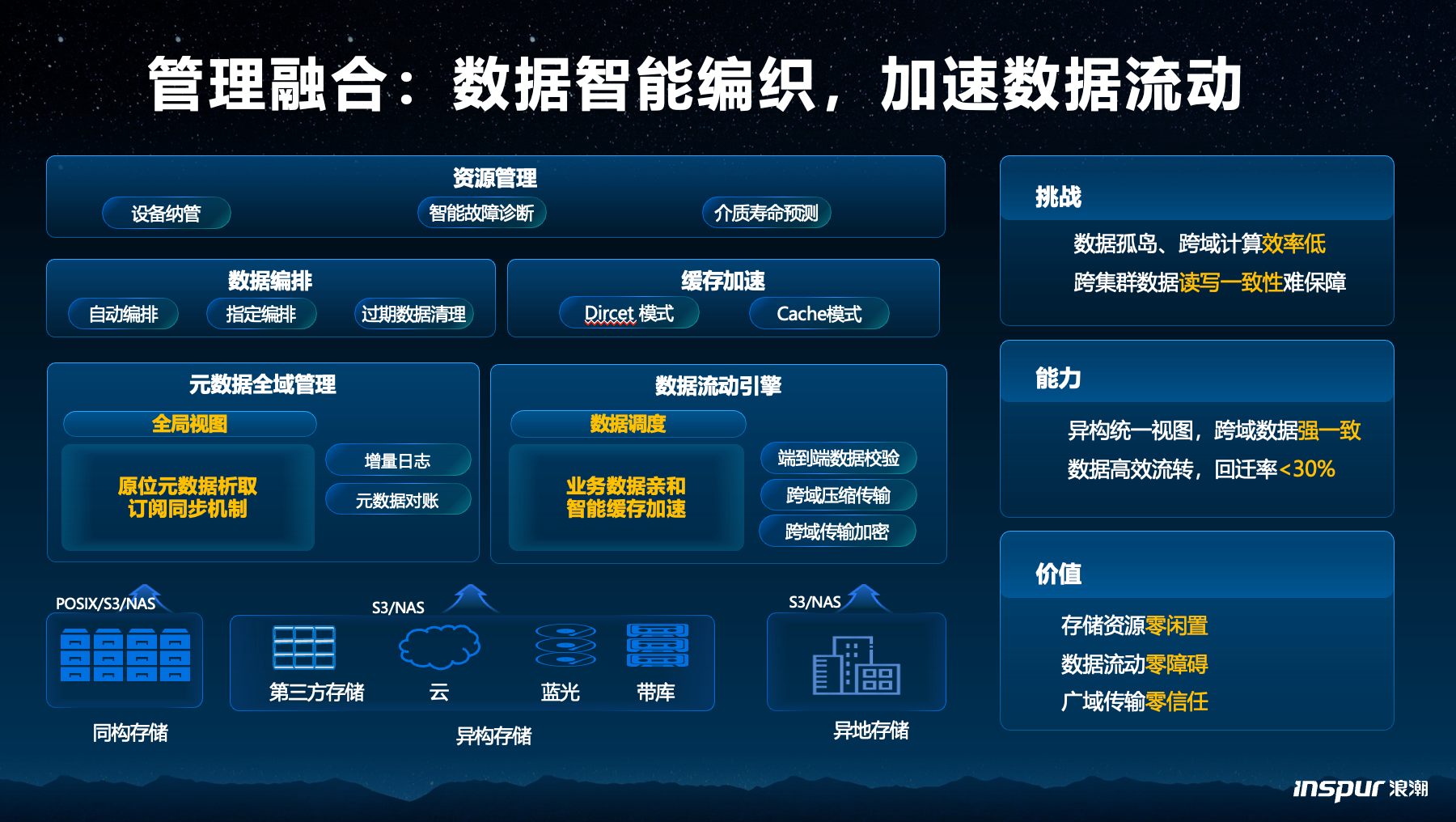
第三个是管理融合,很多企业的数据中心都是分阶段建设的,而且经常会跨地区建设,每次建设可能都用了不同的厂商、不同架构、不同版本。结果就是同一家公司内部的存储资源互相之间都是孤岛,跨域数据一致性很难。
浪潮数据的方案是做统一硬件接口,把所有存储资源统一到一个全局视图,然后通过增量日志和元数据对账等机制保证跨域数据的强一致性。同时,数据流动层面做了智能访问加速,回迁率降到30%以下,加速了数据的高效流转。

最后是应用融合。现在做大模型推理,HBM容量是个硬约束条件,直接影响上下文的长度和用户响应速度。另一块是RAG(检索增强生成),知识库的更新经常滞后到小时级,时效性跟不上业务需求。浪潮数据在这里做了两个关键技术:
一个是KV Cache融合,通过语义驱动的缓存调度,将平均吞吐提升2倍以上。KVCache融合还支持通过KV操作硬件加速,从而将延迟降低70%,这种方案可以支持一百万Token的超长上下文。
另一个是RAG计算融合,多源异构数据自动格式解析与元数据提取,以及流失数据做分布式存储与RAG数据库之间的数据变更同步,把RAG数据的更新延迟从小时级压到分钟甚至秒级。
浪潮数据落地国内万亿参数大模型存储方案
张业兴也提到了浪潮数据落地的国内万亿参数大模型存储案例,堪称业内标杆。浪潮数据服务的一家大模型算力租赁服务商,主要面向国家实验室和高校提供算力租赁服务,集群规模有1500个CPU节点和2500个GPU(8卡)节点,运行着万亿级参数的大模型。
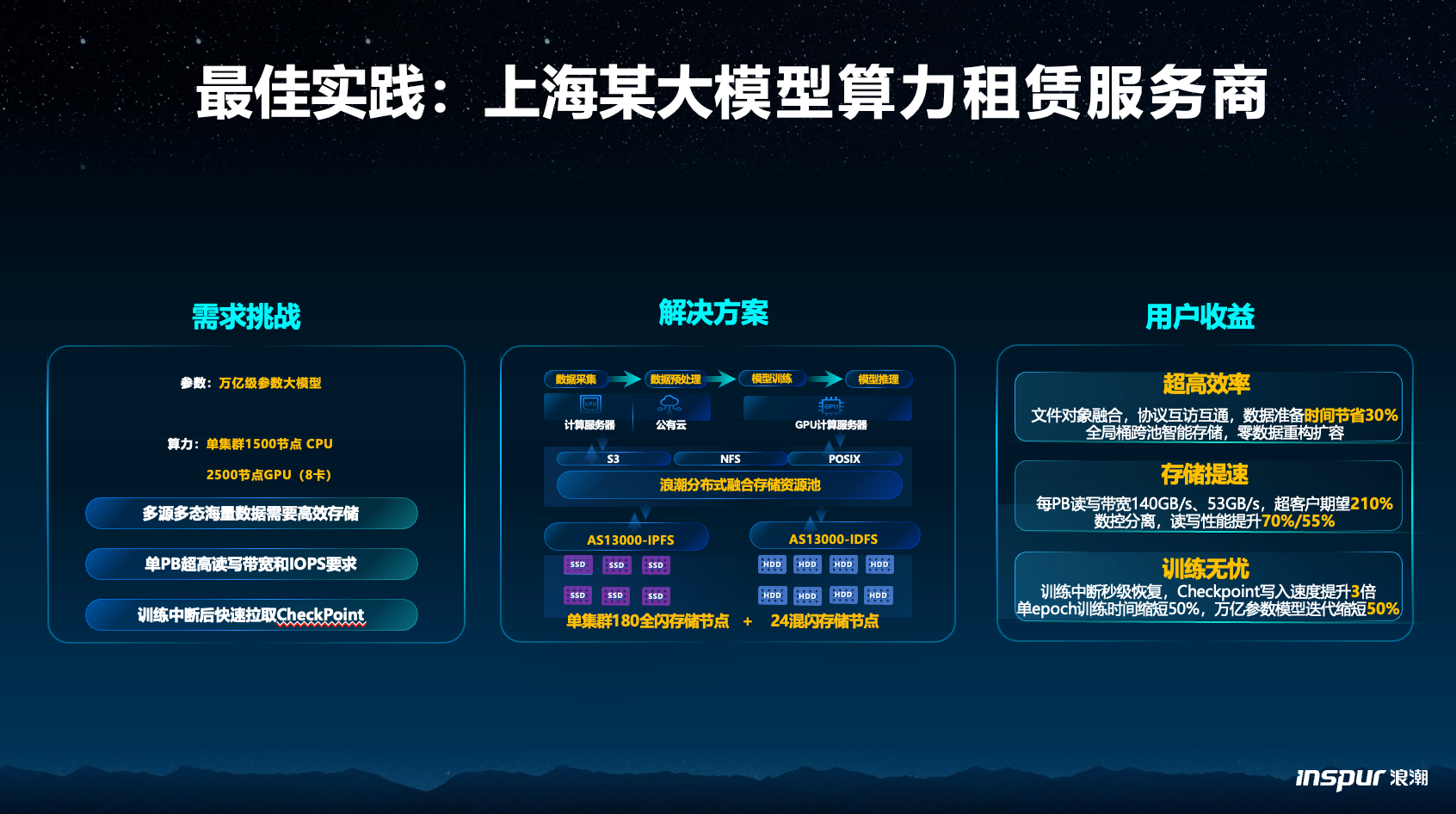
他们对存储的需求有三个,首先,由于模型需要的数据非常多,所以需要存储能装下多源多态海量数据;第二,需要存储具备极高的IOPS和带宽性能来跟计算匹配,避免算力浪费;第三,需要存储支持CheckPoint的快速拉取来节省时间。
浪潮数据给的方案是分布式融合存储资源池,单集群180个AS13000全闪IPFS节点加24个混闪节点。经过几期建设,客户机房里现在跑着500多个IPFS全闪节点和100个混闪节点。
在这套方案的支持下,通过协议融合成功将数据准备时间节省了30%,利用高达140GB/s、53GB/s的读写带宽,提供远超用户预期的数据供性能。更快的Checkpoint写入性能,也让万亿参数模型更让训练时间节省了50%。
结束语
仔细聆听完这场演讲,我认为,这场分享最值得记录的不是某个具体的产品参数,而是张业兴抛出的那个判断:智算中心的基本矛盾,正在从算力不够用转向存力不够用。而这,关系到企业AI基础设施领域的投资决策和AI战略能否落地。
如果AI基础设施领域的重心确实在转移,那么浪潮数据提到的四个融合,可以理解成是这个迁移过程中,他们给出的具体技术答卷。答卷做得怎么样,最终还是要看更多客户落地之后的实用反馈。从浪潮数据在分布式存储市场的积累来看,他们至少有交出这份答卷的底子。
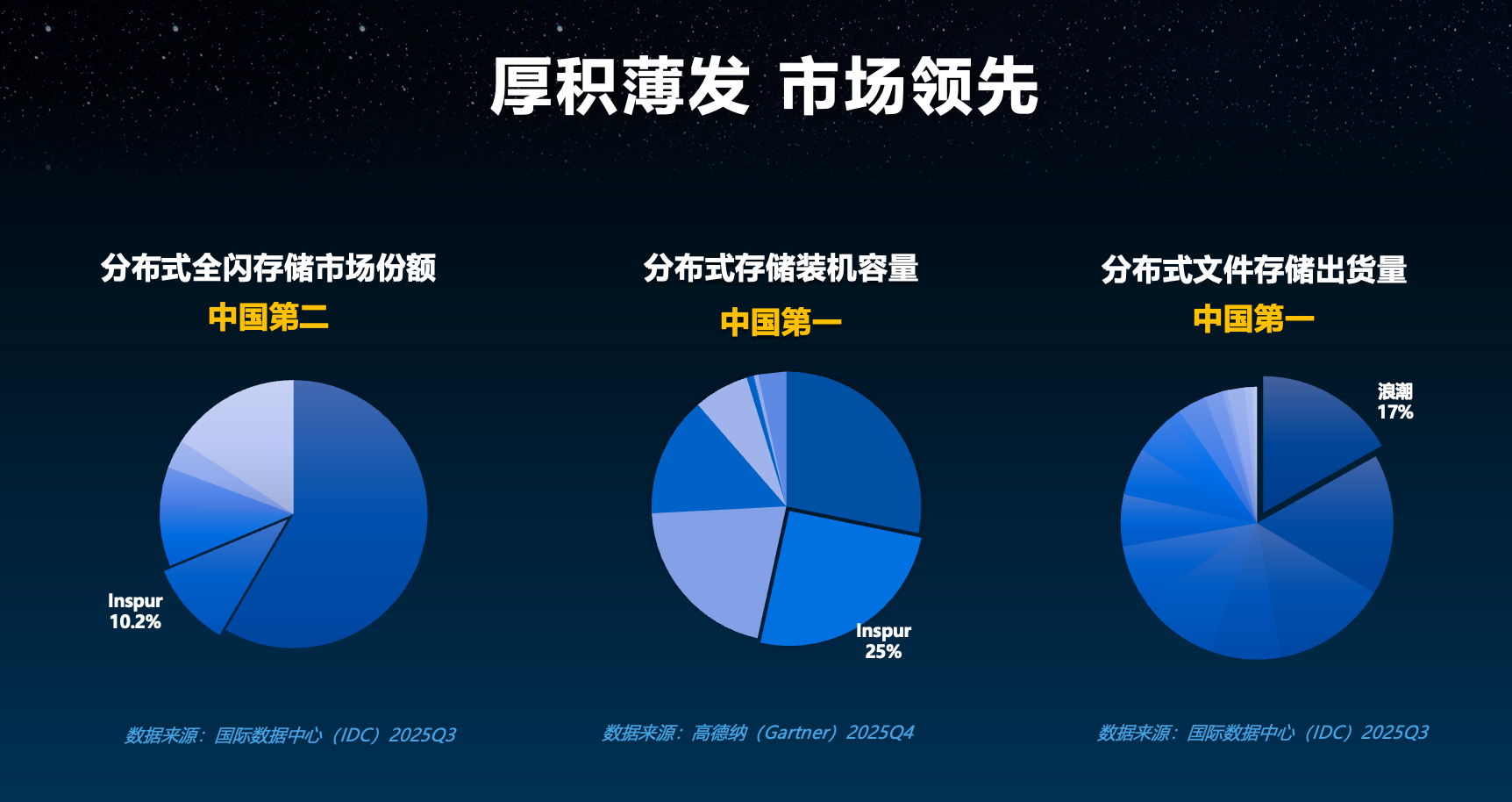
浪潮数据是浪潮集团旗下子公司,在分布式存储领域有优势地位。IDC 2025年Q3数据显示,其以整体市场10.2%的份额,位列中国第二,分布式文件存储出货量以17%的份额位列第一。Q4数据中,其在分布式存储装机容量上以25%的份额位列第一。



