ЯаСФOracle ExadataгыHadoop
ВЉПЭyangdigital ЗЂБэгкЃК12Фъ12дТ10Ше 00:47 [зЊди] DOIT.com.cn
ЖўЁЂOracle ExadataМмЙЙ
НщЩмЭъHadoop КѓЃЌЮвУЧдйРДПДвЛЯТOracle ExadataЕФМмЙЙЃК
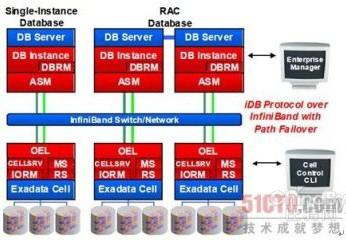
ШчЭМжаЫљЪОЃЌOracle ExadataЪЧгЩМЦЫуНкЕуКЭДцДЂНкЕуЙЙГЩЃЌЭМЩЯВуЮЊМЦЫуНкЕу,ЯТВуЮЊДцДЂНкЕу,МЦЫуНкЕуКЭДцДЂНкЕуОљЮЊX86ЗўЮёЦїЃЌДцДЂНкЕуЪЧX86ЗўЮёЦїжБСЊДцДЂ(DAS)ЕФЩшМЦЃЌМЦЫуНкЕуПЩвдзїOracle RAC(HAЃЌИКдиОљКтЃЌВЂааМЦЫу)ЃЌМЦЫуНкЕуМфЛЅСЊвдМАМЦЫуНкЕуКЭДцДЂНкЕуМфЕФЛЅСЊЖМЪЧВЩгУInfiniband(ИпДјПэЃЌЕЭбгГй)ЃЌЖјВЛЪЧДЋЭГЕФвдЬЋЭјЁЃећИіЯЕЭГжаЭјТчВПЗжЖМгаШпгрЃЌЩшМЦЮЊЮоЕЅЕуЙЪеЯЁЃ
МЦЫуНкЕуБОЩэВЛДцЗХЪ§Он,ЫќЭЈЙ§ASMФЃПщЗУЮЪДцЗХгкДцДЂНкЕуЕФЪ§ОнЃЌOracle ЕФASMЪЧOracleЙЋЫОздМКЕФздЖЏДцДЂЙмРэШэМўЃЌЬиБ№ашвЊзЂвтЕФЪЧ:ASMЪЧOracle ExadataМмЙЙЗЧГЃКЫаФЕФВПЗжЃЌБОЮФжївЊЬжТлЕФОЭЪЧExadataжаЕФASMвдМАSmart Scan(Offloading)ММЪѕЃЌЦфЫќШчSmart flashcacheЃЌStorageindexЃЌHCCЕШЬиадЃЌБОЮФВЛзїЬжТлЁЃ
гЩгкOracleЕФЮФЕЕжаЖдгкExadataжаASMММЪѕЯИНкЕФУшЪіВЛЖрЃЌвђДЫБОЮФжагааЉЙлЕуЪЧЮвБОШЫЕФВТВтЃЌШчгаУ§ЮѓЃЌОДЧыСТНтЁЃ
вдЯТгаЙиASMЕФзЪСЯКмЖрРДздгкЁЖOracle+Database+11g+RACЪжВс(Ек2Ац)ЁЗвЛЪщ
ASMгыOracle Ъ§ОнПтНєУмМЏГЩдквЛЦ№ЃЌВЂЖдЦфНјаагХЛЏЁЃЫќЪЧЭЈЙ§3 ИіЙиМќзщМўЪЕЯжЕФЃКASM ЪЕР§ЁЂASM ЖЏЬЌОэЙмРэЦї(ADVM)КЭASM МЏШКЮФМўЯЕЭГ(ACFS)ЁЃASM ЖЏЬЌОэЙмРэЦїЮЊASM МЏШКЮФМўЯЕЭГЬсЙЉСЫОэЙмРэЦїЙІФмЁЃ
ASMПЩвдгЕга63 ИіДХХЬзщЃЌЦфжаЗХжУ10 000 ИіASM ДХХЬЃЌУПИіASM ДХХЬПЩвдДцДЂИпДя2TBЪ§ОнЁЃвЛИіДХХЬзщПЩДІРэ100 ЭђИіASM ЮФМўЁЃдкOracle Database 11g жаЃЌвЛИіЪ§ОнЮФМўЫљжЇГжЕФзюДѓЮФМўДѓаЁЮЊ128TBЃЌЖјASM дкВЩгУЭтВПШпгрЪБжЇГжИпДя140PB Ъ§ОнЁЃПЩМћASMЫљФмЙмРэЕФДцДЂПеМфвВдк100PBЕФСПМЖЁЃ
вдЯТЪЧOracleдкЪЙгУASMЧАКѓЕФМмЙЙЖдБШЃК
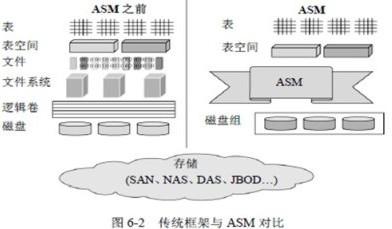
ExadataЪЙгУASMЙмРэЫљгажЧФмДцДЂНкЕуЩЯЕФгВХЬЃЌЫќЪзЯШАбЫљгаДцДЂНкЕуЕФДХХЬЗХЕНвЛИізЪдДГиРя,ВЂаЮГЩACFSМЏШКЮФМўЯЕЭГ,ШЛКѓгІгУ Stripe And Mirror EverythingММЪѕАбашвЊДцДЂЕФЫљгаЪ§ОнЮФМўЗжИюГЩЙЬЖЈДѓаЁЕФПщЃЌОљдШЕФЗжВМЕНИїДцДЂНкЕуЕФгВХЬЩЯЃЌВЂПЩвдЖдЪ§ОнПщЩшЖЈИББОЕФЪ§СПЃЌГЃЙцЪЧЫЋжиИББОЃЌИпМЖЪЧ3жиИББОЁЃИББОЭЈГЃвВЛсБЛЗХжУгкЦфЫћДцДЂНкЕуЕФгВХЬЩЯЁЃвђДЫЕБМЦЫуНкЕуашвЊЗУЮЪФГИіЪ§ОнЮФМўЪБЃЌвВЪЧашвЊЕНЖрИіДцДЂНкЕуЩЯВЂааЖСШЁЁЃДгетЕуЩЯПДЦ№РДЃЌASMдкЮФМўЗжИюКЭИББОЗНУцЕФВпТдЪЧЗёгыHDFSЕФЫМТЗКмЯѓ?ВЛЭЌЕФЪЧOracle ASMвЛАуЩшЪ§ОнПщДѓаЁЮЊ128KЛђ1MЃЌЖјHDFSвЛАуЩшЮЊ64MЁЃ
дкExadataДцДЂШнСПВЛЙЛЪБЃЌвВПЩвддкЯпЬэМгДцДЂНкЕуЃЌASMдкДцДЂХфжУКЭдйХфжУЦкМфЃЌВЛашвЊШЮКЮЭЃЛњЪБМфЃЌвВОЭЪЧЫЕЃЌдкИФБфДцДЂХфжУЪБВЛашвЊЪЙЪ§ОнПтЭбЛњЁЃдкДХХЬзщжаЬэМгЛђЩОГ§ДХХЬжЎКѓЃЌASM ЛсздЖЏдкДХХЬзщЕФЫљгаДХХЬжЎМфОљдШЕидйЗжВМЮФМўЪ§ОнЁЃетИіВйзїГЦЮЊ“ДХХЬдйОљКт”ЃЌЫќЖдЪ§ОнПтЪЧЭИУїЕФЁЃЕЋOracle ExadataЖдДцДЂНкЕуЕФЬэМгЪЧгавЊЧѓЕФ,ЫќУПДЮРЉШнзюЩйашвЊРЉ1/4ЛњМм,вВОЭЪЧ4ИіДцДЂНкЕуЁЃФПЧАExadataзюДѓШнСПжЛжЇГжзюДѓ8ИіЛњМмЃЌЕЋЮвЯраХЪЧгЩгкНЛЛЛЛњгВМўМмЙЙЕФЯожЦЃЌЖјВЛЪЧASMБОЩэЕФЯожЦЁЃ
ЬжТлЕНЯждкдйЛиЭЗПДПДЃЌHadoop HbaseЪЧЙЙМмгкHDFSЩЯЕФNosqlЪ§ОнПтЃЌExadataдђЪЧЙЙНЈгкASMЩЯЕФoracleЪ§ОнПтЃЌДЫЭтExadataЪЙгУЕФASMКЭHDFSЪЧгаКмЖрЯрЫЦЕФЕиЗНЁЃЧАУцЮвзмНсЕФHDFSЕФ4ИіжївЊЬиЕужаЃЌПЩРЉеЙадЃЌЖрДХХЬВЂЗЂЙЄзїЃЌИпПЩгУетШ§ИіЬиадЃЌдкExadataжаЖМгаРрЫЦЕФЪЕЯжЗНЪНЁЃ
гЩгкASMЕФзЪСЯНЯЩйЃЌЮвВЛЪЧКмЧхГўExadataжаASMЕФдЊЪ§ОнЕФЙмРэЗНЪНЃЌвђЮЊДгExadataЕФМмЙЙЩЯПДЃЌУЛгаРрЫЦгкHDFSЕФ NamenodeЕФНЧЩЋЃЌвђДЫACFSПЯЖЈВЛЪЧВЩгУМЏжаЪНдЊЪ§ОнЗўЮёФЃаЭЁЃЮввВдјЧыНЬЙ§Б№ШЫЃЌгаШЫЫЕЪЧВЩгУРрЫЦGlusterFSЕФЕЏадHashММЪѕЃЌСэЭтгаШЫЫЕЪЧВЩгУЗжВМЪНдЊЪ§ОнЗўЮёФЃаЭЃЌЕЋЮвДгOracleЕФЮФЕЕЩЯПДЕНЃЌдЊЪ§ОнЪЧДцЗХдкУПИіжЧФмДцДЂНкЕуЩЯЕФЃЌвђДЫЮвИќЧуЯђгкКѓепЁЃетИіашвЊЪьЯЄ OracleЕФИпЪжНтЛѓ!
зюКѓдйРДПДвЛЯТExadataЕФСэвЛИіжївЊЬиадSmart Scan(Offloading)
ЯТЭМЪЧSmart Scan(Offloading)ЕФЙЄзїЪОвтЭМЃК
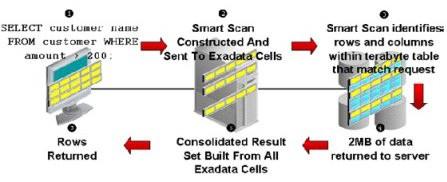
1ЁЂПЭЛЇЖЫЯђЪ§ОнПтМЦЫуНкЕуЗЂГіСЫвЛИі SELECT гяОфЃЌДјгаЮНДЪЃЌвЊЧѓЙ§ТЫВЂНіЗЕЛиЫљашааЁЃ
2ЁЂМЦЫуНкЕуЪ§ОнПтФкКЫШЗЖЈДцДЂНкЕуПЩгУЃЌВЂЙЙдьвЛИіДњБэЗЂГіЕФ SQL УќСюЕФiDB УќСюЃЌВЂНЋЦфЗЂЫЭЕНИїДцДЂНкЕуЁЃ
3ЁЂДцДЂНкЕуЕФ CELLSRV зщМўЩЈУшЪ§ОнПщвдЪЖБ№ФФаЉааКЭСаТњзуЗЂГіЕФSQLЁЃ
4ЁЂДцДЂНкЕужЛНЋТњзуЮНДЪЕФааКЭЧыЧѓЕФСаЗЕЛиИјМЦЫуНкЕуЁЃ
5ЁЂМЦЫуНкЕуЪ§ОнПтФкКЫећКЯИїИі Exadata ЕЅдЊЕФНсЙћМЏЁЃ
6ЁЂзюКѓЃЌНЋВщевЕНЕФааЗЕЛиИјПЭЛЇЖЫЁЃ
МђЕЅЕФЫЕЃЌExadataЕФSmart ScanЙЄзїФЃЪНОЭЪЧЃКЕБМЦЫуНкЕуНгЕНПЭЛЇЖЫШЮЮёЪБЃЌЫќОЭАбШЮЮёЯТЗЂИјИїИіДцДЂНкЕуЃЌИїДцДЂНкЕуМЦЫуЭъКѓдйАбНсЙћЗЕЛЙИјМЦЫуНкЕуЃЌзюКѓгЩМЦЫуНкЕуећКЯГЩЭъећНсЙћМЏЃЌдйЗЕЛиИјПЭЛЇЁЃ
ЫМПМвЛЯТExadataЕФетИіЬиадЪЧЗёКЭMapReduceжаЕФJobtrackerЃЌTasktrackerЕФЙЄзїФЃЪНКмЯѓ?ЖМЪЧMasterНгЕНПЭЛЇЖЫШЮЮёКѓЃЌАбШЮЮёЗжНтГЩЖрИіаЁШЮЮёЃЌШЛКѓгЩЖрЬЈSlaveВЂааМЦЫуЃЌзюжеАбЛузмНсЙћЗЕЛЙИјПЭЛЇЖЫЁЃгЩДЫЪЧЗёПЩвдЫЕExadataЕФSmart Scan(Offloading)ММЪѕвВЗћКЯЧАЮФзмНсЕФMapReduceЕФСНИіживЊЬиадЃК1ЁЂЖрНкЕуВЂааМЦЫуЃЌ2ЁЂДѓСПашвЊМЦЫуЕФЪ§ОндкБОЕиЃЌжЛгаМЦЫуВњЩњЕФжаМфНсЙћЛђНсЙћВХдкЭјТчРяДЋЪфЃЌДѓДѓМѕЩйСЫЭјТчСїСПЁЃ
ЧАЮФНщЩмЙ§ЃЌHBaseКЭHiveЖМЪЧЭЈЙ§КмЖрНкЕуВЂаазїMapReduceМЦЫуЃЌРДЬсИпећЬхЯЕЭГЕФЭЬЭТСПДгЖјКЃСПЪ§ОнЕФВщбЏКЭЗжЮіФмСІЃЌЦфЪЕ ExadataвВВЩгУРрЫЦЕФМмЙЙЃЌЧјБ№ОЭЪЧДцДЂНкЕуЩЯВЛЪЧХмMapReduceЃЌЖјЪЧХмSQLЖјвбЁЃЕЋВЛПЩЗёШЯЕФЪЧHadoopжЇГжГЩЧЇЩЯЭђИіНкЕуЕФМЏШКЃЌЖјФПЧАExadataжЛжЇГж8ИіЛњЙёЃЌвђДЫДгРЉеЙадЗНУцЃЌЛЙЪЧЮоЗЈКЭHadoopМЏШКБШЁЃ
злЩЯЫљЪіЃЌЦфЪЕExadataНшМјСЫЗжВМЪНМЦЫуЕФКмЖргХЕуЃЌЫќАбRDBMSЙЙНЈгкЗжВМЪНМЏШКДцДЂжЎЩЯЃЌДгЖјЪЙЕУRDBMSОпБИСЫИќКУЕФРЉеЙадЃЌДЫЭтЫќЛЙЮќШЁСЫжкЖрРрЫЦгкFlashЃЌInfinibandЃЌСаЪНЪ§ОнПтЕШаТММЪѕЕФЬиЕуЃЌВЂНЋетаЉММЪѕЭъУРЕФШкКЯдквЛЦ№ЁЃВЛПЩЗёШЯЃЌOracleЕФExadataЪЧЙиЯЕаЭЪ§ОнПтСьгђРяЮАДѓЕФИяаТадВњЦЗЁЃ
ЙигкOracle Ъ§ОнПтЃЌExadataЃЌRACЃЌASMЃЌACFSЕШММЪѕЃЌгаЗЧГЃЖрЕФФкШнЃЌЖјЮввВЪЧдкПЊЪМбЇЯАЕФЙ§ГЬжаЃЌБОЮФжЛЪЧЮвдкбЇЯАЙ§ГЬжаЕФвЛаЉзмНсКЭИаЯыЃЌЮвОѕЕУМЦЫуЛњММЪѕжаКмЖрЖМЪЧЯрЭЈЕФЃЌЕБвЛИіСьгђРягаКУЕФММЪѕЗЂВМжЎКѓЃЌЦфЫћСьгђЕФММЪѕШЫдБЛсбИЫйбЇЯАВЂНшМјетаЉММЪѕЃЌДгЖјЭЦЖЏздМКСьгђЕФММЪѕЗЂеЙЃЌетвВЪЧаХЯЂММЪѕдкетаЉФъРяЗЩЫйЗЂеЙЕФдвђ!



