由于数据量和并发访问量的急剧增加,数据库的连接遇到瓶颈,大数据量的访问速度慢、效率低的问题日益突出。对于海量数据的处理,非关系型数据库使用日益增多,如何部署分布式数据库,解决关系数据库和非关系数据库的共同使用以及大数据量的表访问效率低的问题已成为重中之重,通过把数据拆分到不同的数据库,在应用层对不同数据源整合的方案,是解决数据层性能问题的关键。
1 、数据拆分
随着网络流量爆发式的增长,业务拆分势在必行。拆分的业务形成一个个独立的子系统,RS10系统包括生产、物流、财务等子系统,每个子系统之间耦合度低,功能模块划分清晰,数据易于拆分。把生产、物流、财务等子系统的数据从存放在一个数据库服务器上拆分成存放在不同的数据库服务器上,通过中间数据层框架进行数据整合,使得业务层访问数据仍像访问单个数据库一样,不造成任何影响。业务分级与关联是业务划分、信息共享和资源整合的过程,使用数据层框架解决分布式数据库对业务分级和关联带来的影响。通过分库分表、读写分离,数据库的性能问题也迎刃而解。
数据拆分就是通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。数据拆分同时还可以提高系统的总体可用性,即使单台设备崩溃之后,只是总体数据的某部分不可用,而不是所有数据。
数据拆分根据其拆分规则,可以分为两种拆分模式。一种是按照不同的表拆分到不同的数据库(主机)之上,这种拆分称之为数据的垂直拆分;另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种拆分称之为数据的水平拆分。
1.1 垂直拆分
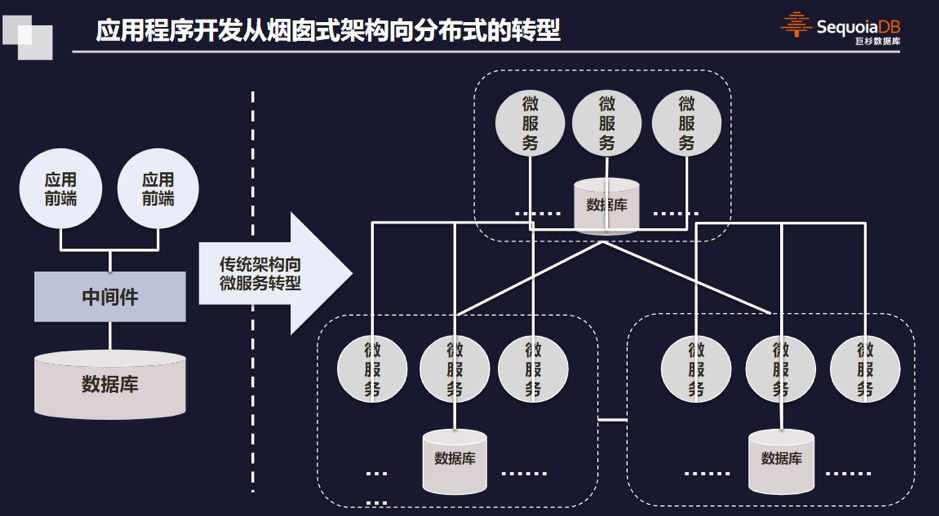
数据的垂直拆分,也称纵向拆分,数据库是由很多个数据块组成,我们垂直的将这些数据块拆开,将他们分散到多台数据库主机上面。
一个架构设计较好的应用系统是由多个功能模块所组成的,而每一个功能模块所需要的数据对应到数据库中就是一个或者多个表,不同功能模块的数据存放于不同的数据库主机,可以有效避免跨数据库的连接存在。
垂直拆分的架构,如图1所示:
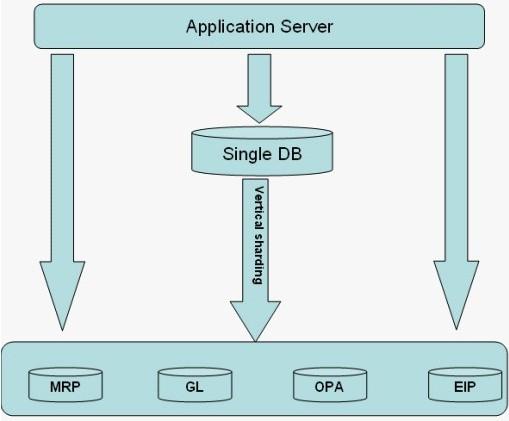
图1 垂直拆分架构图
垂直拆分的优点表现在:
1、数据库的拆分简单明了,拆分规则明确;
2、应用程序模块清晰明确,容易整合;
3、数据维护方便易行,容易定位。
垂直拆分的缺点则表现在:
1、部分表关联无法在数据库级别完成,需要在程序中完成;
2、频繁访问超大数据量的表时会存在性能瓶颈;
3、事务处理更加复杂。
1.2 水平拆分
水平拆分是将访问频繁的大数据量的表,按照某种规则拆分到多个表中,每个表只包含一部分数据。
数据的水平拆分是按照数据行的拆分,将表中的某些行拆分到一个数据库,而另外的某些行拆分到其他的数据库中,且拆分时需按照特定的规则来进行,如根据公司号或者用户编码等进行拆分。基于用户的编码进行数据水平拆分,如图2所示:
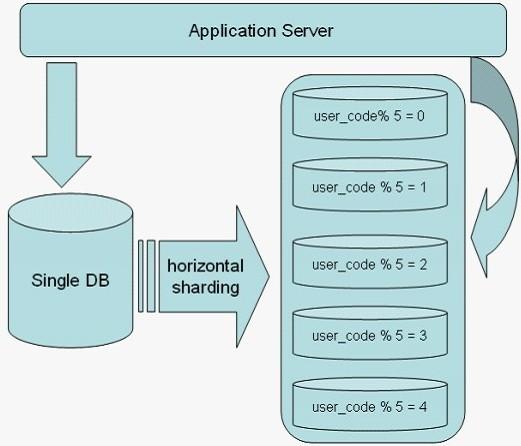
图2 水平拆分架构图
水平拆分的优点表现在:
1、表关联能够在数据库端全部完成;
2、不存在超大型数据量和高负载的表;
3、事务处理相对简单;
水平拆分的缺点则表现在:
1、切分规则较复杂,很难抽象出一个满足能整个数据库的切分规则;
2、后期数据的维护难度有所增加,人为手工定位数据更困难;
3、应用系统各模块的耦合度较高,对数据的迁移拆分造成一定的困难。
1.3 联合拆分
在实际的应用场景中,系统的业务逻辑比较复杂,系统负载比较大,无法通过单独的一种数据拆分方式来实现,需要两种拆分方法结合使用,分布式数据库应采用垂直拆分与水平拆分联合的方式,如图3所示:

图3 联合拆分架构图
联合拆分的优点:
1、可以充分利用垂直拆分和水平拆分各自的优势而避免各自的缺陷;
2、系统扩展性得到最大化的提升。
联合拆分的缺点:
1、数据库系统架构比较复杂,维护难度更大;
2、应用程序架构相对更复杂。
2 、数据整合
数据库在经过垂直和(或)水平拆分被存放在不同的数据库之后,RS10系统最大的问题是访问业务数据,让业务数据得到较好的整合,因此,存在两种解决方案:
第一种方案,在每个子系统中配置和管理需要的数据源,直接访问各个数据库,在每个子系统内完成数据的整合;
第二种方案,使用数据层框架来统一管理所有的数据源,数据库集群对每个子系统透明。针对RS10,我们采用第二种解决方案来实现数据的整合。
3、分布式数据库层架构
在选择通过数据库的中间代理层来解决数据的拆分和整合方案之后,我们选取开源的Amoeba框架,在它基础上开发出适合RS10的数据拆分和整合方案。
Amoeba 是一个基于java开发的,专注于解决分布式数据库数据源整合的开源框架,可用来监视、分析或者传输他们之间的通讯信息,实现连接路由、Query分析、 Query过滤和修改、负载均衡以及基本的HA机制等。所有客户端请求都是通过这个中间层,然后经由中间层进行相应的分析,判断出是读操作还是写操作,然后分发到相应的数据库服务器上,我们基于这个框架来实现和部署RS10的分布式数据库,架构图如图4所示:
图4 分布式数据库层架构
Amoeba能解决RS10以下问题:
1、RS10分库分表以及拆分之后数据的整合;
2、提供了数据拆分规则,降低拆分规则给数据库带来的影响;
3、减少了数据库与客户端的连接数,用户只访问自己需要的数据;
4、通过中间层代理,实现读写分离。
基于这个开源框架我们能开发出同时连接不同的数据库的数据源为前端应用程序提供服务,我们通过Amoeba框架分析Query语句,根据Query 语句中所请求的数据来自动识别Query语句的数据源是什么类型数据库在哪个物理主机上面,然后选择特定的JDBC驱动和相应协议连接后台数据库。
通过数据的垂直和水平拆分,增强数据库的整体服务能力,通过数据层框架解决数据拆分和整合,使数据库很容易扩展,只需要增加廉价的PC服务器,即可线性增加数据库集群的整体服务能力,从而实现分布式数据库的部署和扩展。
4、结束语
目前,关于分布式数据库系统数据处理的研究很多,针对RS10大数据量的性能以及并发访问效率低的问题,基于Amoeba框架,对大数据量的表进行 拆分,对集中式部署的数据库采用分布式部署,有效的解决数据量大、并发访问效率低的问题。分布式数据库对数据的拆分和整合是最关键的环节,只有充分解决这 个问题,分布式数据库才能得到有效地使用。