
许多人认为RAID已经死了,但是它可能像凤凰一样,借助一些新的技术浴火重生。
这些新技术中最新的,最值得人们研究的就是NetApp的动态硬盘池技术(DDP)。借助这项技术,人们可以解决RAID长久以来的问题,使它在未来获得更好的发展。
RAID的问题
RAID是一种最常见的存储技术。它可以让用户把存储媒介连接成组,从而获得更大的容量,提升性能或减少硬盘失效带来的损失。对于大部分RAID来说,我们要损失一点总容量,因为要存储冗余的校验信息,或者建立一个镜像。
可是,就像人一样,RAID也垂垂老矣了。
使用RAID-5或RAID-6,你也许会失去一个硬盘,但是不会丢失任何数据。在RAID-5或RAID-6中,如果一块硬盘出现故障,借助剩余的硬盘或冗余校验信息,数据可被重新建立,借助其它硬盘进行读取。
举个例子,如果你在一个RAID组中(比如RAID-5或RAID-6)安装了10块3TB的硬盘,你不得不读取剩下的9块硬盘中每个硬盘单一的块。可以说这是利用27TB的数据去重建3TB的数据,读取这么多数据可能会花费很长的时间。剩余的9块硬盘都将写入到一个目标空间,但是性能不会被重建。而且,当这样的重建进行时,RAID组还在使用中,重建速度会更慢。另外,如果我们使用的是RAID-5,再损失一块硬盘我们就不能复原任何数据了(使用RAID-6的话再损失一块硬盘我们勉强还能承受)。
现在,我们使用的硬盘容量都是3TB,4TB,甚至能达到5TB,6TB。在RAID-5或RAID-6中,如果我们有10块6TB的硬盘,当一块硬盘出现故障时,我们需要读取修复的数据总量为9*6即54TB的数据,这样才能复原6TB数据的损失。请注意,硬盘的速度没有变快,所以读取这些硬盘的总时间要比现在长得多(就像是,读取性能不变,但是要读取的数据总量增加了)。
而且,用户还很有可能遇到URE(不可恢复读取错误)问题,URE表示的是读取之前出现读取错误的数据总量(比如说,控制器无法读取特殊的块)。当RAID重建开始时,这个问题非常重要,因为RAID组中剩余硬盘所有的容量都要被读取——即使在块中没有数据。
在某些情况下,出现URE的概率非常大(比如说出现不可读取的块),这意味着重建会失败。如果使用的是RAID-5,这意味着重建已经失败了,数据不得不从备份中提取。即使你使用RAID-6,现在你也有两个失败点了——第一个是失效的硬盘,第二个是出现URE的硬盘。RAID-6重建可以继续,但是已经失去保护了。如果再出现一个错误,RAID组就完了,数据要从备份中读取了。
当然,存储公司们已经意识到了这个传统的RAID问题,它们推出了许多技术保证重建进程的顺利实施,即使出现了URE,也可以提供保护。举个例子,在RAID-6中,一块硬盘出现故障了,如果你有一块冗余硬盘,那即使出现了URE,重建也不会被终止。这可使管理员继续进行RAID组的重建,但是这只是应用到RAID-6中(可以承受两块硬盘出现故障)。
还有一个方法,我还没有见过,但是应该存在,就是在重建过程中跳过出现URE的块,阵列会完成重建但是无法告知用户哪个块出现了问题。当然,与出现问题的块相关的文件没有被完全重建,但是这可以使用户重建其它的数据。这种方法要比从备份或副本中重新读取54TB的数据要好得多,因为从理论上来看,你只需要读取被损坏块影响的文档就可以了。
因此,传统RAID组的问题是
1. 硬盘容量越来越大,RAID组中的硬盘数量会减少(RAID-5和RAID-6都是这样的情况),但是还会出现URE。
2. 重建时间变得越来越长,因为读写性能保持不变,但是RAID组要处理更多的数据了。
这些问题,当然还有其它问题的出现,使得RAID的光明前景变得黯淡无光。硬盘容量越来越大,RAID的未来却越来越迷茫。许多人还预测几年之后 RAID将终结。但是现在出现了新的技术可以改善这种情况。在这里我想介绍这样一种技术,动态硬盘池(DDP),这项技术将使RAID重新焕发出生机。
NetApp的动态硬盘池
NetApp提出了名为动态硬盘池的概念,可以改善传统RAID遇到的问题。这个概念非常简单——仍然利用RAID,但是不采用整块硬盘,而是利用 更加颗粒化的结构。NetApp还推出了最新版本的SANtricity软件,这家公司把DDP和RAID-6整合起来,应用到更加颗粒化的层面。DDP 允许用户把所有的硬盘连接起来,应用到控制器的后端,建立一个存储池。这就像经典的RAID-5或RAID-6,但是用户可以在单一的池中使用所有的硬 盘,而不用把它们分解到RAID-5或RAID-6中再利用逻辑卷管理程序或其它技术把他们连接起来。为了更好的理解这项技术如何工作,我们需要进一步了 解DDP的整体结构。
DDP的最低水平被称为D-Piece。一个D-Piece是一个硬盘中连续的512MB片段,由4096个128KB的片段组成。下一个水平被称 为D-Stripe,由10个D-Piece组成,因此一个D-Stripe总共有5120MB的原始空间。D-Piece是利用伪随机算法从存储池各种 硬盘中挑选出来的。每个D-Stripe基本上就是一个RAID-6组,拥有8+2的配置(8个数据和2个冗余块),这意味着在一个D-Stripe中, 我们有8*512MB,即4096MB的可用空间。最终,D-Stripe可以建立一个卷来满足用户需要的容量。
在DDP中,我们仍然采用了RAID的概念,比如说采用RAID-6。但是不像以前利用整块硬盘作为RAID-6的块,DDP打破了硬盘,把它们分成小块,横跨所有的硬盘创建了RAID-6的结构。
请看图一,这张图片是由NetApp提供的,阐述了如何由12个硬盘建立一个DDP。(版权归NetApp所有,未经许可不得使用)
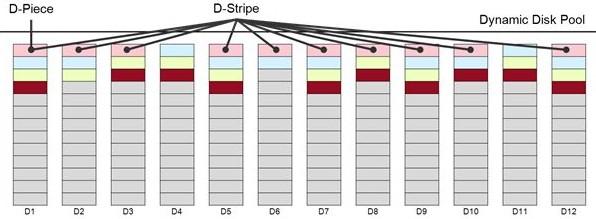
在图一中,每个块是一个D-Piece(512MB)。相同颜色的D-Piece组成了D-Stripe。举个例子,所有粉色的D-Piece组成 了一个D-Stripe,而浅蓝色的D-Piece组成了另外一个D-Stripe,所有黄色的D-Piece形成了第三个D-Stripe,深红色的 D-Piece形成了另外一个D-Stripe,依此类推。
在特别的D-Stripe中的D-Piece是以某种随机的方式选择的,所以这种特别的布局无法重复。选择过程在保持伪随机布局的同时尝试平衡各个硬盘的容量。这就保证在两个D-Stripe上的所有数据的位置在10个硬盘中的位置相同这种纯随机情况不会发生。
在一个运行系统中,一个DDP要被创建首先要确定池中硬盘的数量。然后用户要根据所需的容量大小来建立一个卷。软件可在池中横跨所有的硬盘建立D- Piece,接着创建D-Stripe。卷是由一些D-Stripe建立的,尽可能使用整数单元的D-Stripe,满足用户所需的容量。你可以在同一个 DDP中创建一些卷,前提是DDP的容量够用。
下面让我看一下在DDP中如果一个硬盘出现故障会怎样。图二(NetApp提供)展示了如果6号硬盘出现故障会怎样。(版权归NetApp所有,未经许可不得使用)
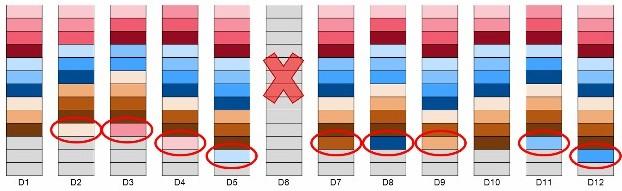
硬盘的失效使得有一些D-Piece在损坏硬盘中的D-Stripe无法继续工作。因此,这些受到影响的D-Stripe需要被重建。一般情况 下,DDP会有一些多余空间来应对硬盘失效。也就是说,用户没有使用DDP中所有的空间,在卷中留下了一些可能用到的附属容量,它们将在重建时被使用。需 要注意的是DDP中的重建与传统的RAID重建不一样,D-Piece和D-Stripe要被重新生成,因为硬盘中的平衡被打破,重建需要确保数据分布的 伪随机性。
在一个有10+2布局的“正常”RAID-6中,当一个硬盘出现故障时,只有11个硬盘参与到重建中,它们都写入到一个单一的空闲硬盘“目标”。但是这样重建的时间就要受到硬盘数量的限制,还要受到硬盘写入速度的限制。
在有着相同数量硬盘的DDP中,整个硬盘池都参与到重建中来。这意味着我们可以有更多数量的硬盘为重建服务,还会有更多的读写,同时还会进行再生和再平衡,进一步改善性能。所有这些都意味着DDP的重建要比传统的RAID-6速度快得多。
还有一点与传统的RAID不同的地方是,DDP的重建只需要读取受影响的D-Stripe所需要的D-Piece。未受影响的D-Stripe中的D-Piece不需要再次读取。这意味着我们不需要读取整块硬盘,让用户远离URE的危险区域。
在重建过程中,失去两个D-Piece的D-Stripe将获得优先权,防止再次发生会导致受影响的D-Stripe复原失败的故障。记住D- Stripe是借助RAID-6建立的,现在两个RAID-6组都出现问题了,如果第三块再出现问题,那用户的数据就会受到损失了。既然数据在控制器中, 那两个D-Piece可以同时进行再生,全面恢复受损的D-Stripe。这使得损失两个D-Piece的D-Stripe再次出现故障的可能性变得非常 小。
在一个硬盘出现故障的情况下,有两个或更多受影响D-Piece的D-Stripe的平均数会非常低。这意味着关键D-piece的重建会非常快 (别忘了它们只有512MB大小)。重建速度太快以至于附属的硬盘会在几分钟内失效,但是不会造成数据损失。这一点值得注意——使用DDP用户可以损失超 过2块硬盘。所以当RAID-6在更低的层次使用,DDP却可以承受两块或两块以上硬盘的损失而不会造成数据丢失。
NetApp表示安装12块1TB的硬盘(12块硬盘是DDP的最小数量),传统RAID-6组(10+2)的重建时间为大约11个小时,而相同配置的的DDP仅用7个小时就可以实现完全的重建。虽然这看上去不像是一个多么重大的进步,但是重建的时间减少了36%。
另 外,请注意这是完全复原。在一些受影响的D-Stripe中使用RAID-6冗余的速度非常快,可以保护不会再次发生硬盘故障。对于一个传统的 RAID-6来说,用户不得不等11个小时才能实现完全的RAID-6保护。然而,借助DDP,你可以快速获得一些受到RAID-6保护的D- Stripe,随着重建的进行,受到RAID-6保护的D-Stripe数量会不断增长。
你可以比较一下传统的RAID-6和DDP的复原能力。只要一块硬盘出现故障,传统的RAID-6就会在低级模式下运行(只有一块硬盘进行复原), 但是在重建完全完成之前,传统的RAID-6不能进行完全冗余。DDP重建和再平衡的速度非常快,所以DDP的部件可以随着时间推移不断获得RAID-6 保护。
比较一下结果
在未来会出现一些技术,可以让用户拓展或代替RAID带来的收益。现在就有一个例子——NetApp的 动态硬盘池,为用户提供更多的收益。首 先,DDP很容易理解,因为它本身就是RAID。可是,它又不是像创建RAID组那样有固定的硬盘规格。而且,它能扩展潜在的RAID块,在池中横跨所有 硬盘随机设定,形成RAID-6的8+2的模式。
第二,在出现硬盘失效的情况下,借助DDP,用户可以让更多的硬盘加入到重建过程中,它们都可以进行读写,消除单一硬盘写入性能的限制。这将大幅减少恢复时间。
第三,在重建过程中,只有丢失的D-Piece被重建。而在传统的RAID-6中,用户需要读取剩余硬盘的所有空间,即使有的空间并没有被使用——这将使用户很容易遇到URE的问题。
而 且,在传统的RAID-6中,如果不进行完重建,用户就不能获得RAID-6保护(也就是说,在每样东西在完成之前,它就不是100%)。而在 DDP中,一些D-Stripe可以快速获得RAID-6的保护。随着复原的推进,整个池获得RAID-6保护的比例将不断增加。所以,这不是一个“要不 全部都是,要不一个没有”的命题。
除此之外,在DDP中很容易创建所需容量的卷,还可以在池中留下多余的容量。当用户有需要的时候,可 以继续在池中增加卷。而且,DDP可以动态监控 潜在容量(当然,你需要扩展文件系统)。使用传统的RAID,用户需要创建新的卷,把它增加到现有的池中,在这过程中还要利用一些逻辑卷管理器,还要增加 文件系统。
最后,使用DDP意味着用户可以承受失去两块以上的硬盘。如果传统的RAID-6在一个LUN中失去了2块以上的硬盘,这个LUN就不能再重建了,数据只能从备份或副本中获得。在DDP中,一个单一池可以损失多块硬盘,数据也不会丢失。
但 是,每样事物都有利有弊。在DDP中如果一块硬盘出现故障,大量的硬盘将参与到重建过程中,这将会对某些性能方面造成不利影响。在NetApp的 动态硬盘池中,你可以关掉重建的“优先权”,这样对性能的影响会小点。或者你也可以打开优先权,让重建尽快完成。这就取决于你了,你得自己考虑哪方面比较 重要。
总结与展望
RAID,目前还起着重要作用,但是也将不久于人世了。硬盘容量在不断增加,但是硬盘 的速度和URE率却没有多大变化,传统的RAID不会存在太长 时间了。以后将会出现大量改进版RAID,为用户提供相似的功能,但是却免受原来问题的困扰。其中一些方法会非常复杂,非常昂贵,这样的方法也不会被普遍 采用。
在这篇文章中,我介绍了一种方法,利用了RAID的概念,但是却更加颗粒化。NetApp的动态硬盘池借助RAID的概念创造出 了新的解决方案,可 以让用户以更简单的方式把硬盘整合到一个单一的池中。它还能允许系统失去两块以上的硬盘(正是这个导致了RAID-6的失效)。这个好东西还很容易被理 解,所以我们不需要消耗多年的时间重新研究RAID的知识。
硬盘容量不断增加,数据的数量也呈几何级不断增多,像DDP这样的方式会变得越来越重要。传统的RAID不得不为其它方式让路,否则我们将会面临数据丢失的危险。



