
6月13日,在“数据中心和人工智能技术首映式(Data Center and Al Technology Premiere)”上,AMD宣布了基于“Zen 4c”核心架构的AMD第四代EPYC 97X4系列处理器(代号为“Bergamo”)三款新品,以及采用AMD 3D V-Cache 技术的第四代AMD EPYC 9004X处理器系列(代号“Genoa-X”)三款新品,前者提供云原生计算所需的线程密度和规模,后者适合最苛刻的技术计算工作负载,以满足数据中心的创新应用。
当天,AMD还发布了面向高性能计算和人工智能工作负载的加速器Instinct MI300内部架构。
Zen 4c架构与Zen 4架构的相同与不同
据AMD技术专家Silicon设计工程师Mike Clark介绍,Zen 4c架构跟Zen 4架构均采用5nm制程,在能效、密度以及性能方面都有比较理想的设计,理论上二者大量相关的应用软件都是完全一样的。

但差距无疑也是存在的,而且很大。

如每CCD上核心数量从Zen 4架构的8个提升到了Zen 4c架构的16个(相当于每socket上的核心数量增加了33%),原因在于优化后的Zen 4 L3级Cache从4MB降低至2MB,使得每核面积从3.84平方毫米降低至2.48平方毫米,这种优化后的核心布局,最终导致单个EPYC处理器新品Bergamo实现了最高128个Zen 4c核,进而能够支持更多的吞吐量,满足高负载应用场景下对性能的需求。
另外,Zen 4核心最高主频为6GHz,但因为Zen 4c作为云上数据中心应用,无需如此之高的主频,所以AMD在Zen 4c上适度进行了降频,达成较好的能效。
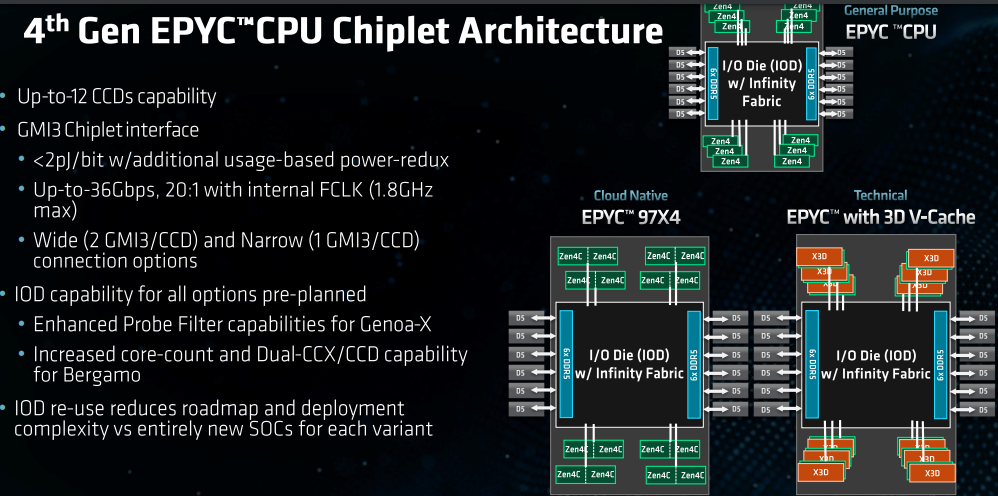
基于Zen 4c架构的 EPYC 97X4与EPYC 9004X系列
聊完Zen 4与Zen 4c的差别,再来看看同样基于Zen 4c架构的处理器有哪些异同。
实际上,二者在内存、SP5平台、集成IO-无芯片组以及安全方面的性能几乎如出一辙,如都是12通道DDR5内存, ECC频率同样高达4800MHz,可选2/4/6/8/10/12通道存储器交互,3DS RDIMM,一个2插槽系统可扩充至高达12TB (256GB 3DS RDIMM) 2个DIMM /通道容量;全新的Socket插槽提升了电力输送和支持VR,都采用多达4条速度高达32Gbps的第三代AMD Infinity Fabric链路,多个服务器控制器集线器(USB、UART、SPI、I2C等);最多160条 I/O通道(2P)的第五代PCle接口,传输速度高达32Gbps,以及可以利用CXL协议扩展的内存寻址功能;增强的专用安全子系统、安全的引导与基于硬件的信任根,采用SME与SEV-ES以及SEV-SNP、AES-256-XTS以及更多加密的虚拟机技术。

尽管双方在最多核心(达128个核心)、最高功耗(400W)、die-to-die带宽等方面表现一致,但采用Zen4c架构的EPYC 97X4系列(最多8个CCD、256线程) 、每核提供1MB L2缓存、每个CCD提供2个 16MB L3缓存;而EPYC 9004X最多12个CCD / 6个内核/ 192线程、每核1MB L2缓存、每CCD 96MB L3级缓存,L3缓存提升至原先的3倍,总计可达1152MB。
L3缓存的显著提升,进一步降低了内存延迟,同时也提升了大数据量计算时处理器的性能。这成为EPYC 9004系列的一大显著特征。
AMD服务器SOC Silicon设计工程师Kevin Lepak强调,AMD作为芯片架构的领导者,推出了超越摩尔定律的模块化、可配置设计,以领先的工艺节点、先进的包装3D堆叠技术(3D V-Cache)来加速性能提升,降低电力和成本效率。
“事实上,我们不希望轻易改变I/O架构,不论是在SoC还是在I/O Die的大小,这样OEM伙伴或者合作伙伴能基于我们的产品进行设计与部署。”Kevin Lepak说。
AMD 3D V-Cache技术:超越摩尔定律
当工艺演进到5nm甚至3nm节点,提升晶体管密度越来越难,由于集成度过高,功耗密度越来越大,供电和散热也面临着巨大的挑战。
AMD高级副总裁、产品技术架构师Sam Naffziger研究员表示,通过改善封装技术,可在同样面积上汇集更多相同或者不同的工艺节点制造的小芯片(Chiplet),从而降低成本的同时获得更高的集成度。
这一技术就是AMD津津乐道的3D堆叠(3D V-Cache)技术,堪称后摩尔时代重要技术手段之一。
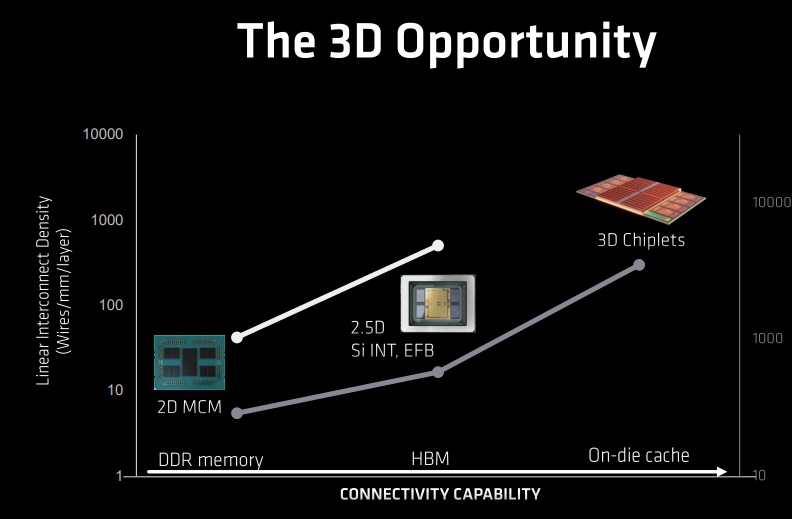
回顾封装的演进过程,从开始的2D多模块铜封装(MCM)、2.5D光封装(Si INT,EFB)到如今先进的3D Chiplets,对应的分别是DDR内存、HBM以及On-die缓存;3D堆栈封装这种设计技术,通过Cache容量的延展,达到了能效的巅峰。
想要在2D芯片上达到3D缓存的性能,基本上是不可实现的:除了其Die非常大,时延会非常长,功耗也非常之高。

3D V-Cache技术比2D芯片封装内部互联密度大200倍,比微微凸起的3D内部互联的密度要大15倍,跟小凸起的3D内部互联的密度大3倍。这种架构,使得在处理EDA工作负载处理方面,Genoa-X比Genoa提升70%。
为什么在3D堆栈上能够达到这么好的效能?一方面,它就正好在CCD之上,而且元器件之间的距离并不远,加上优化后的缓存容量提升到了3倍,功耗也大大降低。
EPYC 9004X系列计算性能的提升,正是得益于3D V-Cache技术的应用,但3D V-Cache技术的价值远不止于此。
展示无处不在的AI愿景
“基于AMD 3D V-Cache技术推出的颠覆性APU(Accelerated Processing Unit)架构,紧密集成领先的5nm GPU和CPU计算,完全共享内存,前所未有的计算密度。”Mike Clark表示,这就是AMD的Instinct MI300系列加速器,它事实上就是GPU Die,是非常独特的独有的3D缓存的Die。
MI300作为异构计算的混合芯片,融合了CPU和GPU的核心,功耗非常低。可以看成AMD把EPYC这个服务器处理器集成到一个GPU里面,共享内存,从而实现非常好的每瓦性能。
MI300分为MI300A和MI300X两款。全球首款用于高性能计算和人工智能工作负载的APU加速器MI300A现已向客户提供样品,MI300X将于第三季度开始向主要客户提供样品。
AMD AI平台战略的发布,为客户提供从云到边缘再到终端的硬件产品组合。通过深入的行业软件协作,开发可扩展且普适的 AI 解决方案。人工智能领域的竞争,序幕才刚刚拉开。


