 存储在线
存储在线5月13日,由百易传媒(DOIT)举办的2021(第四届)软件定义存储峰会在上海召开。在上午的主论坛中,我们邀请到上海交通大学教授、博士生导师吴晨涛作为学术界代表发表《弹性扩展的存储阵列及纠删码技术 》的主题演讲,从软件定义存储市场发展引题,详细介绍当前存储阵列扩展难题和解决方案,及上海交大团队自身提出的一些扩展方法。

以下为速记整理(文字未经演讲人审阅):
今天分三个部分讲,首先谈一下软件定义存储的研究背景,第二是存储阵列扩展难题以及解决方案,第三是我们团队提出的扩展方法,最后总结。
软件定义存储市场发展新动向
现在其实软件定义存储通过创建具体化的存储资源池,可以将我们的创设管理软件与基础设施分离管理,传统意义分为Data plane(数据层)、Control Plane(控制层)、Storage Components(存储组件),SDS市场规模每年在以约25%的速度持续增长,预计到2021年整体市场规模将达到162亿美元。
目前来说整个数据中心是SDS存储的重要组成部分,我们不仅有软件定义存储还有软件定义计算、网络等各方面应用。
通过融合不同的存储设备、不同数据接口、不同类型应用的超融合架构仍然是SDS的主流选择。另一方面,云原生技术对系统硬件操作系统、运行时系统、应用进行了解耦,天然适合软件定义存储环境。
比如现在我们整个云平台,通过把硬件、操作系统软件集群管理和上层应用进行解耦,可以实现整个软件定义存储。比如像以容器、微服务等为代表的云原生技术仍在融入SDS,以适配海量应用的数据访问需求。从数据层来说,是采用分布式文件系统,控制层是采用容器协调器。现在数据存储规模已经在PB级到EB级,文件币将成为SDS的重要应用。
当前存储阵列的扩展难题及解决方案
实际上软件定义存储阵列是软件定义存储的核心组成部分,扩展性对于SDS有非常重要的意义,特别是横向扩展,对数据平面的管理尤为重要。

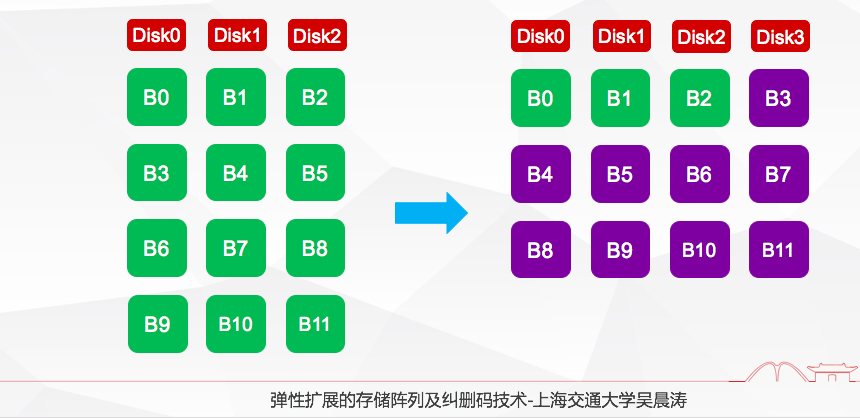
在过去很多年,有非常多的存储阵列扩展方法和算法可以扩展到SDS里面去,像传统的基于Round-Robin的方法,左边图展示了三个盘的数据块数据情况,右边盘是假设新增一个盘,变成四个盘以后的数据分布情况,这个时候我们可以看到相当于采用轮转的方法,除了B0-B2之外,后面紫色的块儿都会进行扩展,相当于它会导致IO的扩展开销很大。
有一些方法,比如采用半轮转方法,它可以比原有的Round-Robin效率方法提高一些,因为我们看到紫色迁移数量变少,但是它多次扩展会导致不均衡的问题。后面扩展方法,只需要迁移少量紫色数据块,达到盘间数据均衡,但是它并没有有效利用条带,存在条带内部存在大量空闲块的现象。
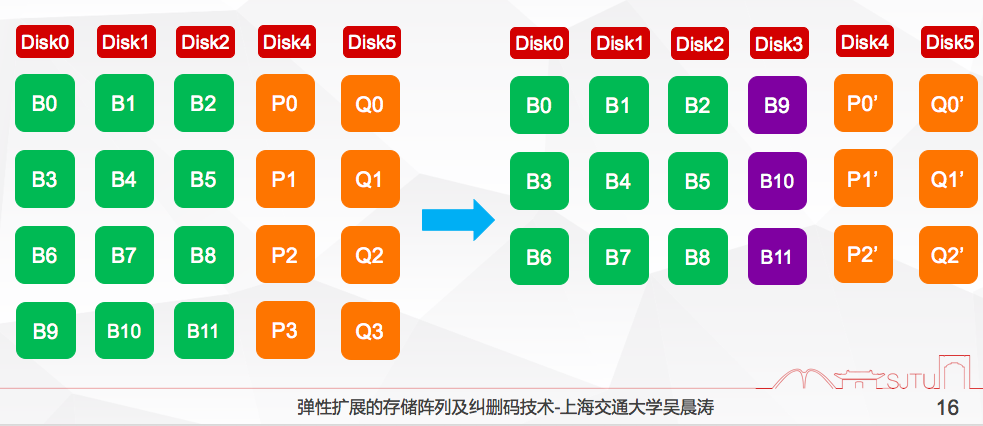
基于GA的扩展方法,可以提高扩展效率,但是由于紫色校验块修改更大,会导致RAID5、RAID6里面,由于所有的校验要重新进行修改、更新,用的时候导致扩展的时间很长。
还有包括CRAID的方法,把热点数据放置在缓存当中进行扩展,冷数据放在硬盘当中扩展,达到较好的扩展效率,但是它并没有调整结合底层的存储阵列以及校验分布,优化底层设备,主要从应用层面角度做这样的优化。
包括现在基于SR编码,对它进行扩展,我们也有一种RS的扩展方法,这里面的扩展是把紫色数据块进行迁移,所有橙色校验块都要进行更新,所以会导致更新效率很低。
实际上现有方法中,我们会面临很多的问题,比如现在的很多扩展方法难以适应云计算、大数据等高效扩展的场景。第二任何扩展方法,都存在一些IO的迁移开销大,迁移路径长,修改过多,然后部分校验方法难以实现整个盘内、盘间的IO分布均衡。
还有大部分扩展方法不一定完全考虑上层应用,比如冷热数据分布的应用,对这个底层扩展的影响,现有的扩展方法也没有考虑到整个大规模部署的情况,比如你的数据迁移不仅涉及到整个云计算的场景当中,不仅涉及到盘内的迁移甚至涉及到节点之间的迁移,还有跨机会之间的迁移及每个数据迁移之间的开销是不一样的,所以我们目前来说方法主要集中在硬盘级别扩展,并没有考虑到整个机柜级别或者数字中心级别的困难,会导致我们场景很难应用的。
上海交大团队提出的新扩展方法
接下来是上海交大团队提出的一些新的扩展方法,结合前面的基础之上,我们做的工作,大概这个工作是跨度有十多年,从最早一篇文章是2011年到今年2021年一直在做这方面的工作。
我们主要针对第一个复杂场景比如RAID5、RAID6,我们分别有自己的扩展方法。
第二我们结合感知上层的应用变化,有针对3盘容错阵列。
对跨机柜扩展场景,我们也有新的扩展方法,从学术圈角度来说我们仅仅把它共享给大家,参考。
第一基于Raid5的方法,我们扩展目标是减少校验的修改,或者保存原有的校验链,基础不动,同时保证数据迁移量足够少,这上面实际对Raid5进行了重新编排,第一个条带我们是原始不动的,包括前面三个条带都是原封不动的,但后面的条带就需要打散重排,所以在我们这里面,有部分的条带是完全不动,有部分条带是打散重排。
由于新的条带需要加入新的数据块,所以这个时候校验计算需要把原始的校验跟新加入的数据块做计算就可以了,这样导致计算量的减少,就不用像前面的方法,把整个校验链打散。这里面我们实现了既可以实现校验修改的开销很小,同时也能实现数据迁移量的数量比较少。
我们做了很多的相关的实验,比如我做了负载均衡的实验,对于不同的扩张场景,我们负载均衡的方差非常少的,可以保证比较好的负载均衡。在负载均衡情况下我们做了数据牵引力的指标,以实现最低的数据牵引力,这个前提是包括所有盘数据是有相同数据量,负载是均衡的。
相当于负载均衡的情况下,我们有一个最低的数据扩展和迁移的时间,我们可以保证数据迁移时间是最短的,扩展需要花的时间也是最短的。一般来说,像正常扩展一个磁盘,四个盘扩到五个盘,每个盘容量一个TB的话,要花几十分钟到一个小时,另外我们在实验当中也证明了逐渐增加硬盘的情况下,还能维持整个高吞吐。
再者针对RAID6的问题,比RAID5更复杂,因为它参与双校验,我们的理念和RAID5的方法也类似,就是维持整个条带尽可能不变,尽可能少的数据做迁移,所以这里面我们实际上是就维持条带不变,但是条带内部的数据做平移,来保证每个条带的数据量是相对来说比较均衡的。
我们也做了很多相关的评估,比如在保证负载均衡的情况下可以达到最低的数据迁移效率,也可以应用在不同的RAID6编码等应用场景。校验修改,可以实现最低的校验修改数量。迁移时间方面我们基本可以达到最低的。
针对三盘容的阵列比双盘更加复杂一些,这里面我们对整个条带进行了重组,融合组内的条带,完成扩展。
我们也可以实现最低的数据迁移率,用了很多编码,也能够实现比较低的校验修改。在保证负载均衡情况下,我们迁移IO比原始的减少70%。并且我们能够实现比较低的内存开销,这里我们是提前感知系统的应用状况和编码参数,做提前的预算。在扩展速度方面,我们基本上可以达到很好的效果。
接下来是考虑应用的情况,相当于感知应用的数据访问情况,我们实际上是根据每个应用的冷热情况,这里面我们写的表示应用访问概率,这时候我们预测一下它的概率,通过机器学习对数据块进行分类,选择特定的数据块,不要求每个盘的数据块数量相同,但要保证每个盘数据访问的次数是基本相等的,说白了负载是基本相等,这样达到平衡的效率。
最终我们比现有的方法,分别可以减少91.5%和50%的迁移开销,这是在RAID5当中,RAID0也可以保证。这种方法只能保证数据的即时性,而不是达到绝对,所以我们大概在保证即时性上,比现有IO大幅降低,在扩展时间上也可以做到大幅度提升。
最后是我们的总结,相当于现在的软件定义存储对阵列扩展性有很高的需求。传统的静态扩展方法难以用适配现在复杂的环境当中,所以针对上述问题,我们交大团队对问题产生了深入的研究,在单盘、双盘、三盘乃至多盘容错阵列中均取得了良好的效果,并且在感知上层应用负载,结合扩展负载进行全局优化。针对大规模阵列场景提出跨机柜扩展方法,适用于不同纠删码场景。
以上就是我的汇报,谢谢大家!