 存储在线
存储在线如果不做技术,在开源的时代,很难跟上步伐。
先不用说技术应用,能把RDS、Redshift、Aurora这些名词搞清楚就不错了!有时候,我就会想:RDS是不是Redshift的缩写呢?
很显然,我们需要一张清晰的产品图谱。
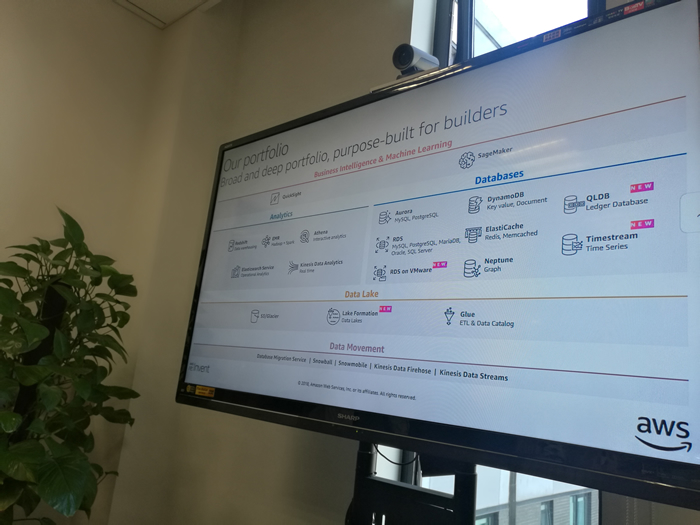
从图中可以看到,无论是数据库,还是数据分析,在AWS,我们都有很多的产品选择。
以数据库为例,有Aurora、RDS、RDS on VMware,有DynamoDB、ElastiCache和Neptune等,与数据分析相关,有Redshift、EMR、Athena、Elasticsearch Service和Kinesis Data Analytics。
不要说我,一个区区的记者,我想即使对于专业技术人员,恐怕也难面面俱到,把这些技术都搞清楚。
不就是数据库、数据分析吗?为什么要搞的这样复杂?
其实道理也很简单。

不同的应用场景,有其适合产品,张冠李戴是不行的。
以前,计算能力有限且昂贵,好钢需要刀刃上。那个时候,数据库和数据分析应用以关系型数据为主,其数据量的占比是10%~15%,但数据价值高达85%;其余85%的数据并不被存储、分析。
但是随着计算能力的提升,特别是Intel x86服务器的广泛应用,计算成本不再是稀缺的资源;与此同时,用户行为等大数据应用备受重视。在这种情况下,各种数据存储和分析工具应运而生,开源技术发展,也发挥了推波助澜的作用。
同样是数据分析,数据类型不同,使用的手段和工具也不尽相同。如数据仓库可以用Redshift,Hadoop+Spark应用可以使用EMR,交互式数据分析使用Athena,实时数据分析使用Kinesis Data Analytics,运营数据分析使用Elasticsearch Service。
数据库也是如此,有关系型数据库,如Aurora、RDS,有键值文档数据库DynamoDB,有图形数据库Neptune,以及ElastiCache等。

互联网用户如Epic Games,这是一家游戏公司,全球都非常知名的“吃鸡”游戏,就是所说《堡垒之夜》就是这家公司的杰作,非常流行的。Epic会把所有用户在线玩游戏中的数据导入到S3中,并利用各种定制化工具,分析用户在游戏中的行为。
可以说,新工具的广泛应用让互联网、网游企业占据了先发的优势,对于传统企业级客户而言,也需要以数据湖为基础,更好地分析数据。
相比于传统的数据库、数据仓库,新的开源软件以及互联网SaaS服务,在性能、成本上都占据优势。
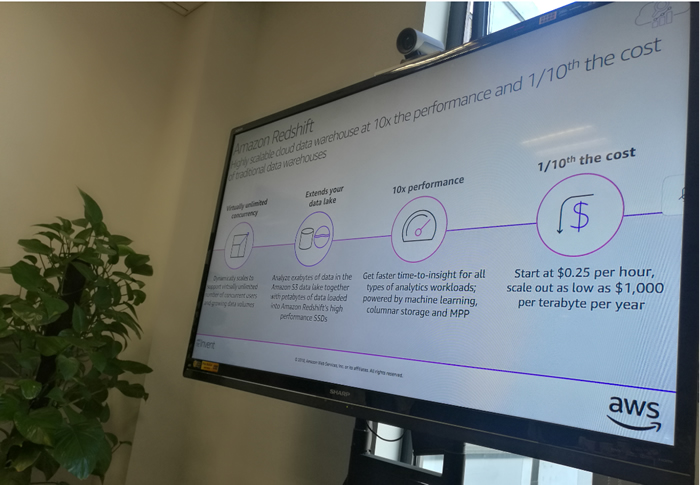
以Redshift为例。传统数据仓库只能够处理GB级、TB级的数据,还没有达到PB级,TB级数据处理就需要大约1万~5万美元。有数据表明,传统数据仓库仅能够处理企业10%左右的数据。为获得更加深远的洞见,企业用户希望能够分析处理100%的数据。依靠传统数据仓库产品,这是不可能的事情。
Redshift的出现弥补了传统应用的不足,它能够处理PB、EB级的数据,处理性能是传统数据仓库的10倍。同样TB级数据处理,所需要的成本仅为1000美元,是传统方法的1/10。
因此,新技术的出现,为企业级用户提供了新的选择。
不同于传统交钥匙的方案,新时期,需要用户有更加广阔的视野,需要具备DIY的能力。在开源、SaaS云服务的世界中,新的技术、功能,无时不刻涌现,将这些技术不断运用到业务创新中,这个是新事情用户必须具备的能力。
“一慢、二看、三通过”已经不符合时代的步伐。
到了需要改变的时候了!加油!