
今日,GitHub技术负责人Jason Warner的一篇技术深度解析稿成为IT圈爆款。文中,Jason坦诚地对外讲述了10月21日100G光缆设备故障后,Github服务降级的应急过程以及反思总结。

从Jason Warner的文章中不难看出,造成断网43秒瘫痪24小时的罪魁祸首是数据库。由于部署在两个数据中心的数据库集群没有实时同步。意外发生时,Github的工程师担心数据丢失,不敢快速将主数据库安全切换到东海岸的备份数据中心。
程序员们在GitHub这篇“忏悔录”下面留言,表达对数据库集群的“哀悼”。但更多IT从业者关心的问题是,如何避免这样的灾难事件降临到自己的公司,自己维护的系统。
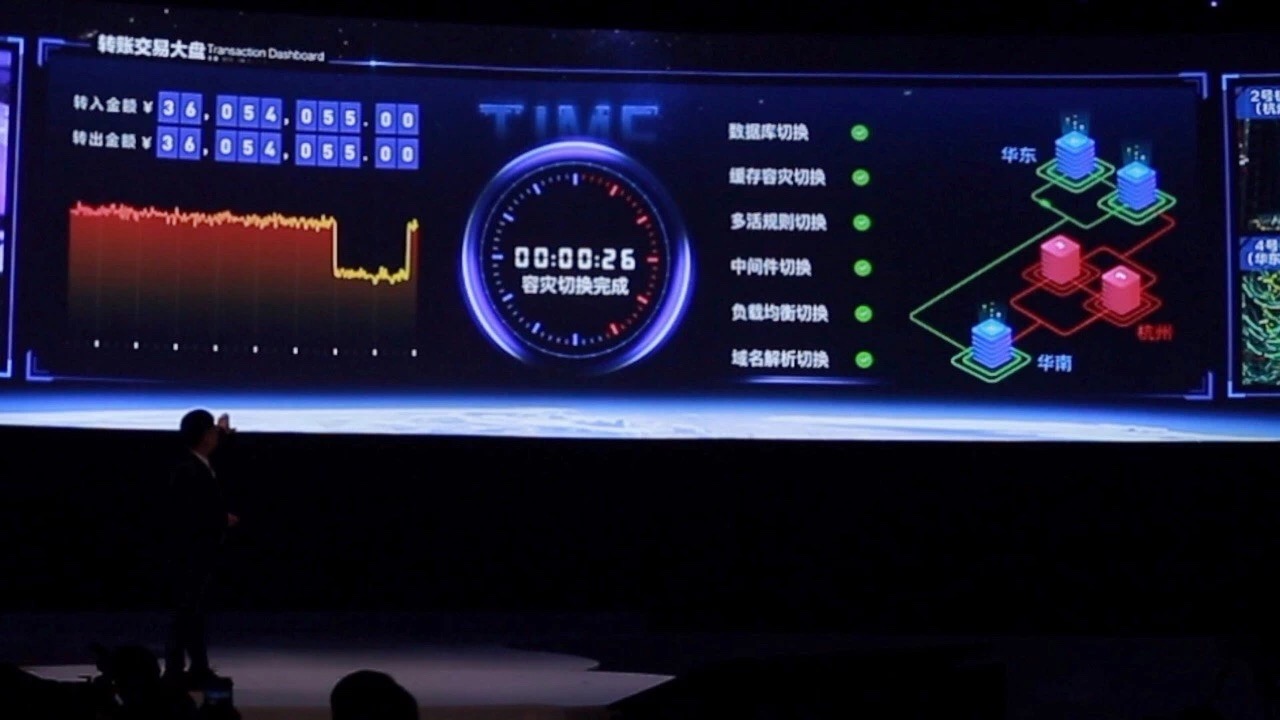
蚂蚁金服OceanBase分布式数据库专家认为,此次Github事件是典型的城市级故障。如果系统采用的是高可用的三地五中心解决方案,就可以自如应对。
就在一个月前,今年的杭州云栖大会上,蚂蚁金服副CTO胡喜现场模拟剪断支付宝近一半的服务器光缆。只用了26秒,模拟环境中的支付宝就完全回复了正常,这背后即是OceanBase城市级别故障的自愈能力。
原来,Github类似银行采用的传统数据库两地三中心模式,即“主库(主机房)+同城热备库(同城热备机房)+异地灾备库(异地灾备机房)”。这种方式下通常只有主机房的服务器能提供写服务。如果主城市出现城市级故障,灾备城市的数据库虽然可以工作,但由于没有同步的最新数据,因此灾备库的数据是有损的。
但在三地五中心部署下,任何单个城市故障,OceanBase都不会停止服务,数据也不会有任何损失。
Github表示,为了保证数据完整性,他们不得不牺牲恢复时间。其实,这个问题采用三地五中心方案可以更好的应对。城市故障时,OceanBase只要活着的两个城市的三个机房两两之间能够通信,就可以正常服务,也不会有任何的数据损失。



