 存储在线
存储在线大数据时代,数据量呈几何增长,为避免被时代潮流“拍在沙滩上”,就必须了解大数据的核心组成要素。其中,海量日志尤为重要,不管是IT达人还是企业本身,掌握海量日志的分析技术都必不可少。
今天,就让小爱带你探秘海量日志分析技术,一起来看吧。
一.为什么海量日志很重要?
在讨论海量日志分析技术之前,我们先来讨论一下什么是海量日志。
海量日志是大数据的重要组成部分。数据仓库之父比尔.恩门(Bill Inmon) 在他的2016年的新书《数据架构》中提到,企业中数据的组成部分中,非结构化的数据占比已经达到了 70% 以上。而这些非结构化数据中,占据主导位置的是日志数据,可以说日志数据是“大数据”分析的核心。
这些数据贯穿所有的企业经营活动,用户的操作行为、服务器的系统日志、网络设备的日志记录、应用程序的调试日志等等,会直接影响企业的日常运行,与IT运维人员也是息息相关。
二.海量日志数据有什么特征?
海量的日志数据十分满足大数据的4V特征:
1. 产生速度快,每秒超过数万、数十万的情况已经比比皆是
2. 数据量巨大,速度一快,如果想要分析这数据,势必会带来巨大的数据量
3. 数据种类多,日志数据涵盖IT系统的方方面面
4. 价值密度低,虽然日志数据中能够分析出大量有价值的信息,往往一条分析结果需要数百万甚至上亿条的数据支撑,而且单条日志的信息量有限
日志样例
我们可以通过一组数据来感受一下海量日志的威力。假设有一个对外应用服务器集群,产生日志的速度为10000条/s,每条日志的平均大小为200字节,那么这个应用服务器每天、每月、每年的日志增量为:

三.大数据条件下计算方式的变革
从行式存储到列式存储,再到流式计算
这么多的数据,我们如何来进行分析呢?一方面我们需要能够处理更多的数据,另一方面,我们希望查询结果更加的实时(例如:1秒之内返回结果)。
如果这些数据在关系型数据库的世界里,数据以行的方式存储,假设我们需要对数以亿计的数据中的某一个数据进行求和计算,那么首先,我们需要将所有这些数据全部读出来,找到对应的字段,然后进行累加,而我们的计算瓶颈完全取决于磁盘的读写能力。
我们可以用分库或者分表的方式将数据库进行拆分,增加系统并行计算的能力,但是可能依然需要数百台设备才能在1s之内返回这些数据。然而我们没有这么多机器,那么只能慢慢等待分析任务执行完毕。如此一来,既耗时又费力。
后来,大数据技术诞生了。在大数据分析的场景中,列式存储架构取代了行式存储。如果要对某一个字段进行统计,只需要读取相应列的数据,不需要进行整个表的遍历,这样一来,需要读取的数据量变小了,同时,MapReduce 也能够使得分析应用更好地实现分布式计算。
可即便如此,计算的瓶颈依然在磁盘的读写效率上,计算速度并没有本质的变化,如果需要做实时数据的分析,还是需要大投入大量的存储和计算资源。
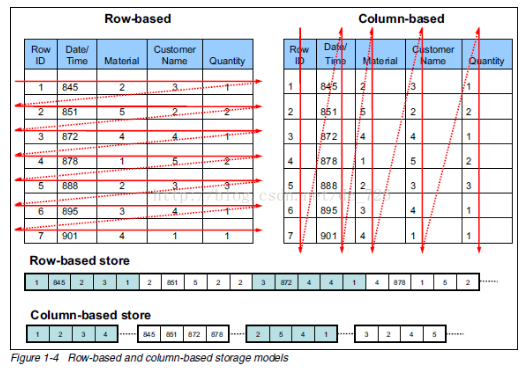
行式数据库vs列式数据库
从逻辑上来说,如果要对海量的数据进行快速的分析,在资源不变的前提下,最好的方法就是减少每次计算所需要读取的数据量。但是如果减少了数据量的读取,分析的结果就无法做到更大的覆盖范围和更加精准的结果。
基于这个思考,我们可以将计算分层,将最近一段时间产生的数据放在实时要求高的数据存储中,使用更好的计算资源来进行分析,将更长时间的历史数据存入离线存储设备中进行批量计算,这部分计算时间可能长达数十分钟或者数个小时,但是计算的结果可以用于和实时分析的结果进行合并,使得分析的覆盖范围和结果的精准度不受影响。
在大数据分析技术中,还有一项非常重要的技术 —— 流式计算,即数据进入系统时就进行必要的预处理操作,这部分的处理,同样减少了后续数据分析中所需要读取的数据量。
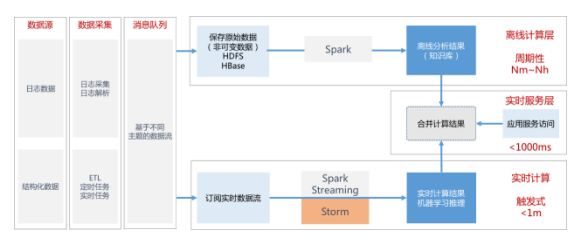
海量日志分析技术数据流程图
四.海量日志分析技术
爱数 AnyRobot Family 3.0(下面简称 AnyRobot) 海量日志分析融入了大数据分析技术,其核心要点在于三个重要方面:海量日志的采集处理、海量日志的存储、海量日志的分析。下面,我们就以AnyRobot为例剖析海量日志分析技术。
1.海量日志的采集处理方面
有两个核心点,分别是数据采集的多样性和实时数据处理的性能。
在采集数据源的多样性方面,AnyRobot 可以对接文件、TCP二进制数据量、压缩文件、结构化数据、Syslog、SNMP 等多种数据源,我们还内置了大量的分析模板,支持市面上多种网络设备、数据库、应用软件、中间件等各类应用,可以实现大部分场景数据的“开箱即用”。当然,数据源的接入也可以通过界面配置的方式快速完成。在实时处理方面,AnyRobot 采用了可扩展的消息队列和流计算引擎,保证了实时处理的性能,能够自如地应对数万甚至数十万每秒的数据流量。
2.海量日志的存储方面
我们采用存储分层的策略对数据进行分层,根据我们上文中探讨的分析思路,应该尽量减少用户在实时分析场景下使用的数据量,我们将分析数据的存储分为三个层次:
第一层:用于实时分析和查询的数据,这部分数据有两个来源。第一部分是短期内进入系统中的数据,这部分数据保留的大量的细节信息,可以用户排错、细粒度的管理分析、事件分析等场景。第二部分是历史数据经过离线批量计算产生的分析结果,这部分数据的细节已经被隐藏起来,主要用户统计分析和报表场景。这一部分的数据由于实时性要求高,也有高可用的要求,因此数据的量多于进入系统的数据量,存储方式可以采用更高性能的 SSD 存储。
第二层:用户存储离线分析的数据,这部分数据是对第一层数据的长期保存和离线分析,这部分数据可以存储在成本更低的对象存储或者云存储中,能够满足小时级别的数据分析和访问需求,需要进行实时分析和日志追溯时,可以重新导入到实时分析存储中去。这部分数据可以通过压缩的方式进行存储,由于日志文件的特性,压缩比最高能够达到原始数据1:5以上。
第三层:归档存储,由于合规性的要求和日志长期保存的需求,可以将更长时间的日志数据通过备份的方式进行归档,采用爱数的 AnyBackup 就能够完成这一工作。这部分数据不需要再实时或者离线分析中进行查看,对它们的历史分析结果已经合并到和上两层的分析当中。这部分数据采用 AnyBackup 自带的压缩和重复数据删除功能,能够获得 95% 以上重复数据删除率

数据分层存储
3.海量日志的分析方面
AnyRobot 实现了一个基于 SPL(搜索处理语言)的搜索引擎,采用分布式计算的方式对数据进行分析和计算,在实时分析方面能够快速的在数亿级别数据量的情况下进行实时分析,同时能够兼容 Hadoop、Spark 等离线分析引擎,并能连接外部数据源,将实时分析、离线分析结果和外部数据源的查询结果合并后呈现给最终用户。
在新版本的 AnyRobot 中也集成了机器学习能力,能够实现异常检测、趋势分析等应用,满足更多使用场景的覆盖。
五.结语
日志是大数据的重要组成,为了满足海量日志分析的需要,我们需要从海量日志处理、存储和分析三个方面来设计我们的日志分析系统。爱数 AnyRobot Family 3.0 通过加入消息队列、流式处理、存储分层、离线分析、机器学习等特性,是的海量日志分析的的效率和用户体验都得到了大幅的提升。