存储在线
存储在线没有计算机网络,则不存在网络存储,特别在分布式计算环境下,尤其如此。过去,数据曾经被认为是一个静态的实体,只支持一个特定的应用,而现在它能为不同地点的许多不同的应用所利用,甚至这些应用可以跨越公司的边界。
数据的这个特征很适合于比作流体,虽然这种比拟与物理学家所定义的“流体”不是一回事,但却有如下的相似性:
. 流体和数据都很容易从一个地方传输到另一个地方。
. 流体和数据一样都很容易通过很长的管道传输。
. 流体和数据都很容易装满容器,而不给其他的物体留有空间。
. 一旦流体或数据流发现一条流入的路径,就很难挡住它的去路。
上面最后一点可能是最令系统管理员害怕的。一旦另一个系统的用户开始访问和存储数据,要想停止他的行为是很困难的。任何对这个问题持有异议的人,只要考虑一下系统管理员如何忙于限制We b文件下载的数量及订阅内容的份数,就会明白他处于何种困境之中。这些下载和订阅不仅使网络性能下降,也使磁盘比以往任何时候都更快地被填满。
流体数据不仅在到达时产生潜在的问题,当目标不接收来自发送系统的数据时,也会出现问题。例如,一个分散的商业公司的经营是以库存和仓库容量为基础的,如果这些报告不能按期到达,则购买系统不能以最高效率运作。
1. 流体数据源的识别
管理流体数据要从识别数据源开始,通常的流体数据源有:
- . 企业资源计划(E R P)系统,如S A P / R 3。
- . 分布式数据库系统。
- . 电子文档交换(E D I)系统。
- . 电子商务( E C)。
- . 供应连锁管理系统。
- . 软件发布。
- . Internet文件传输。
- . Internet订阅服务。
- . e-mail和文件附件。
术语“结构数据”是对“非结构”的特定应用文件格式而言的,用以表示保存在数据库中的数据,而数据流则包括这两种类型。一般而言,由于结构数据流的源和目的容易识别和度量,所以更易于管理和控制。E R P和E D I是两个结构的数据流的实例,无论是发送者还是接收者,它都是极其重要的。
e – m a i l和I n t e r n e t文件传输是两个非结构的实例,两者都是随机的和不可预测的,也很难对它们进行单独控制和管理。
家庭和办公室的e – m a i l交换是非结构e – m a i l数据流的一个例子。一旦人们养成了习惯,无论数据是私人的还是公司的,所有数据类型都开始流动,因此,用公司的e – m a i l系统来达到私人目的便司空见惯。不同的公司有着不同的e – m a i l系统的管理策略,但很少有公司防止其雇员用这种方式发送e – m a i l,即使在技术上是可能做到的,为了不伤害雇员的士气,公司一般也不限制其雇员利用这种方式发送e – m a i l。
事实上,问题还不只是雇员在工作时用e – m a i l系统达到私人目的,它也对系统管理产生影响。系统管理员必须处理存储所有e – m a i l需要的资源,以及收发e – m a i l对系统性能的影响等现实问题。更为严重的,e – m a i l的多份拷贝也最终扩散到整个网络,并产生存储多份拷贝的问题。如果一个e – m a i l被发送给5 0人,那么将需要存储4 0~5 0份该e – m a i l拷贝。当e – m a i l被转发和拷贝到其他用户时,单个e – m a i l消息的存储量将以指数的形式增长。图1 – 2显示了单个e – m a i l消息是如何产生2 0份拷贝的,这些拷贝都被保存下来。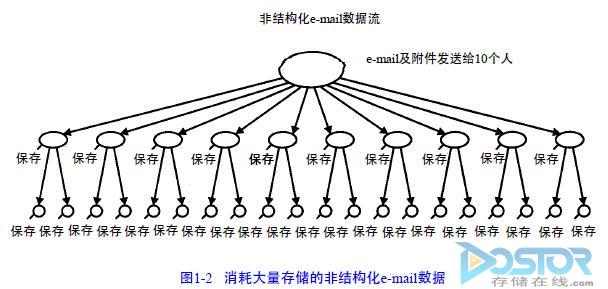
I n t e r n e t订阅服务也会产生类似的结果, I n t e r n e t订阅服务发送各种更新的信息,从股票价格、新闻到天气预报,无所不包。信息驱动的结果之一是当人们希望某条信息时,他们就订阅它。订阅服务系统每天都给办公室工作人员发送许多则消息,这些消息都是他们认为有用的、重要常困难。
软件发布是另一个数据流的源。熟悉I n t e r n e t软件发布的用户经常订阅各种软件服务,这些软件服务包括更新、发布软件信息、预先发布软件的测试版,甚至更严重的情况,这样,一个软件很快就有4、5个拷贝保存在磁盘上,大大消耗网络服务器的存储空间,同时,在这种环境下,计划适合的存储需求也十分困难。
2. 流体数据目标的识别
一旦数据进入一个机构,接下来的问题是:数据应该存放在那里?结构数据很容易跟踪,因为它已经编入了最初存放的地方。然而,事件驱动的应用能够对数据的内容做出反应,并起动一个新的动作将数据传到其他的系统。例如,特许零售商的销售报告先通过电子的形式传到总部,经过正常的处理后,最后再把它传到另一个系统,以计算在销售战中所获得的成果。
E R P系统的设计目的是把分散的全局数据集成为单一的逻辑系统,它的主要思想是以电子的方式连接所有的商业过程,这样就能在整个组织范围内做出更好的决策。依照这种方法,一个部门中的活动可能成为同一公司中另一部门决策的部分信息。举一个简单的例子,假如一个部门库存过剩,则可以把过剩的库存送到另一部门去,以减轻该部门库存压力。
然而,结构数据流的实际目的地不是它所发送的系统,而是连接到这个系统的存储设备。为了真正地了解这些系统的性能,理解从发送机器的设备到目的机器的设备的数据流是很重要的。尽管通常存储成分理所当然地存在,但正如我们在本书大部分章节中所探讨的那样,情况并不是这样。非结构数据流一般有许多种类各异的目标, e – m a i l消息及附件最终散布在各种不同的文件夹、本地磁盘和网络服务器中。图1 – 3显示了一个e – m a i l被同时放在三个不同位置的例子。
出于自我保护的本能,许多用户都坚持把一些文件的多余拷贝保存起来,以备将来万一能用上。但是,当对某一案件作判决时, e – m a i l消息却经常被理解为与政治有牵连,而招致麻烦。这些“可怜人”之所以采用如此的灾难保护办法,是因为过去曾经丢失过大量有价值的资料,因此被弄得焦头烂额,苦不堪言。保存e – m a i l也可能引起麻烦,注意到这一点是饶有趣味的。例如,在1 9 8 7年,由于e – m a i l的摘录,导致了对I r a n – C o n t r a一案审判受到影响。在最近的司法部反托拉斯诉讼案中,内部的e – m a i l信息给微软招致了很大的麻烦。
当然,一旦某个信息被人坚持放入个人归档文件中时,删除它的可能性是很小的。当e – m a i l系统的存储空间太紧张时,系统管理员可能发送e – m a i l给该系统的用户,要求他们删除不必要的信息,也可以通过限制每个用户的存储配额的办法,迫使用户删除不必要的文件。这虽然减轻了e – m a i l系统的存储压力,但用户可能把这些过期的e -m a i l转存到其他地方,以便在必要的时候使用。事实上,差不多没有人有时间重读那些过时的e – m a i l,有些人甚至都来不及阅读当前的e -m a i l。是否保存过期的e – m a i l是一个人对紧缺资源的自律态度问题。现在由于每G B硬盘容量价格的下降,用户并不为节省存储资源而感到烦恼。
I n t e r n e t文件与e – m a i l稍微有点不同,因为当某人认为某We b页面有用或令人感兴趣时,他才去获得并浏览该页面。从这个意义上说, I n t e r n e t文件是政治中性的,与e – m a i l相比,它的保存价值更小。但是它的吸引力在于它是纯粹用来提供知识的,它能使人获得更多的知识、更快的决策、发现问题和识别机会,总之,是能为人类带来荣誉的知识。
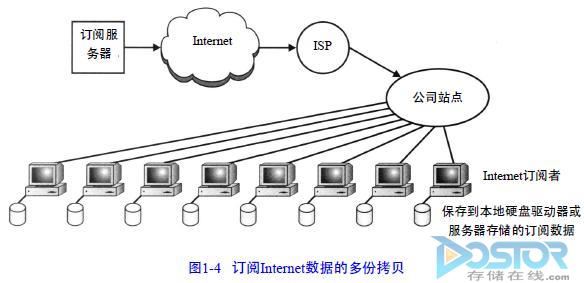
I n t e r n e t的订阅服务带来相当特殊的问题。在同一单位里可能有若干个人订阅同一服务内容的、导致存储同样数据的多份拷贝。图1 – 4显示了由e – m a i l和I n t e r n e t等引起的相同信息的多份拷贝问题,这使得对数据的管理变得相当困难。
3. 结构数据流和非结构数据流的区别
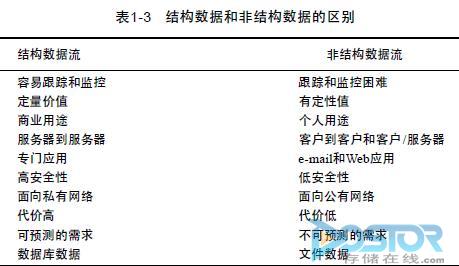
除了结构数据流定义了源和目标以外,它还在多个方面不同于非结构数据,如表1 – 3所示。
4. 管理流体数据
知道结构数据流的源、目标及其支撑的网络技术后,则可以对数据流实施监控,并可以在问题发生之前预测它们。例如,知道平均的数据传输量、它的增长率及网络连接的性能,就可以确定在所有其他因素不变的情况下,现存的网络能维持运行多长时间。
管理非结构数据是一个更困难的任务。不知道数据的源和目标,可资利用的资源又不多。虽然网络的浏览传输能够用一些工具加以过滤和监控,但是用户认为侵犯了他们的隐私,阻碍他们的工作效率。最好的办法大概是建立一个I n t e r n e t内容存储策略,并使人们明白,为了确保有足够的可用资源,这样的责任机制有时是必须的。
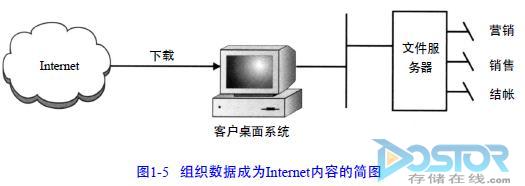
如何将企业的数据组织成为I n t e r n e t内容?一个简单的办法是为那些内容建立部门或功能目录,如图1 – 5所示。在这样的策略下,用户可以养成把下载来的文件存储在他们各自的目录中的习惯。放在功能目录中的文件甚至可以连接到企业We b页面上,以供其他感兴趣的人享用。用户可以通过e – m a i l连接到共享的文档上来交换文件,而不必发送这些文档的整个拷贝。